


编辑:LRS
【导读】80年代,当强化学习被冷落,这对师徒没有放弃;如今,重看来时路,他们给出的建议仍然是,「坚持」住自己的科研思想。
3月5日,计算机学会(ACM)宣布Andrew Barto和Richard Sutton获得图灵奖,以表彰其在强化学习领域做出的奠基性贡献。
自从9年前AlphaGo围棋大胜,引爆全民RL狂欢,再到如今Deepseek-R1等推理模型的火热,足以证明强化学习在人工智能领域的长久影响力。

最近,Communications of the ACM发布了一段对师徒二人的采访,从强化学习的研究经历,聊到对人工智能的未来预测。
Barto侧重于多智能体协作学习,Sutton则认为AGI还需要至少几十年,但最终一定能实现,二人对AI的未来以及强化学习的应用前景都充满希望!
关于两人共同获得的100万美元图灵奖奖金,目前尚未确定具体用途。
Sutton表示可能将其份额捐赠给共同创立的Openmind研究所,给青年科学家提供「奢侈」的科研自由,让他们像自己当年那样专注探索基础性问题。
Barto则计划用奖金在马萨诸塞大学(UMass)设立研究生奖学金。
强化学习萌芽
1975年的斯坦福校园里,当时还是心理学专业的本科生Richard Sutton,翻遍了图书馆里所有关于机器智能的文献,认知受到了巨大冲击。
他对主流的「模式识别」和「示例学习」观点感到失望,认为动物并不是这么学习的,而是通过某种奖励反馈机制(They do things to get rewards.)。
当时,唯一将奖励与学习联系起来的研究人员是美国空军实验室的A. Harry Klopf,认为脑细胞会主动寻求奖励。
Sutton立即决定给Klopf写信,并在1978年心理学毕业后,在马萨诸塞大学阿默斯特分校从事研究,主要工作就是测试Klopf的观点。

团队当时有一位博士后Andrew Barto,在接受空军和国家科学基金会长达五年的资助后,除了一份报告,并没有交付出任何成果。
Barto于1970年获得密歇根大学数学学士学位,1975年获得计算机科学博士学位,最终成为UMass自适应网络实验室(现为自主学习实验室)的联合主任,2012年退休。

Sutton加入实验室后,成为了Barto的第一位博士生,二人最终发展出了现代强化学习技术,奖励也是其中的核心,通过设计奖励信号来训练神经网络,让神经元顺着预期方向发展。
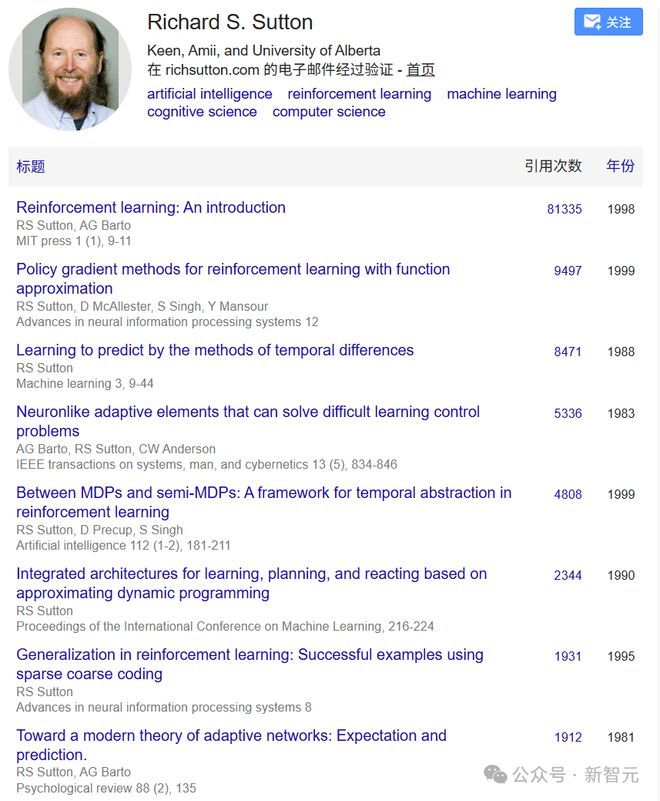
1984年,Sutton在马萨诸塞大学安姆斯特分校(University of Massachusetts at Amherst)获得了博士学位,直到1994年,Sutton都是GTE Laboratories的计算机和智能系统实验室的技术组的主要成员,随后又以资深研究科学家的身份回到了马萨诸塞大学安姆斯特分校。
任职期间,Barto和Sutton共同出版了《强化学习导论》,获得了超8万次引用,2018年又发行了第二版,至今仍是全球AI学子的圣经。

同时,Sutton加入AT&T Shannon Laboratory担任人工智能部门的主要技术组成员,研究方向围绕着决策者与其环境交互时所面临的学习问题,持续改进自己对世界的表征和模型的系统。
2003年之后,Sutton成了阿尔伯塔大学计算机科学系的教授和 iCORE Chair,领导着强化学习与人工智能实验室(RLAI)。
不过,说起强化学习的历史,Barto也提到,他们的思路并不新鲜。
早在1954年,人工智能先驱马文明斯基(Marvin Minsky)的博士学位论文主题就是模拟神经的强化学习系统,也是IBM计算机科学家Arthur Samuel用来训练计算机下棋的方法。

然而,到了20世纪70年代,这个想法已经过时,大多数AI研究员都在设计专家系统,Barto也庆幸自己能够保持「不合时宜」。
Barto和Sutton提出的一个关键技术是「时间差分学习」(temporal difference learning)。
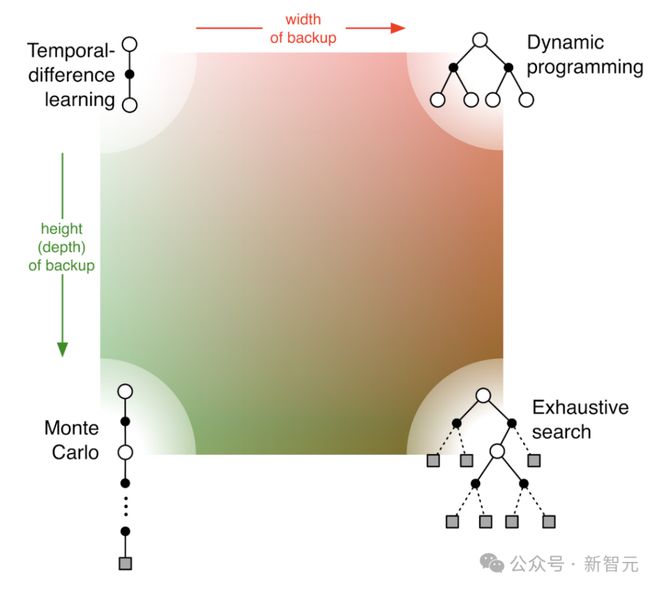
比如,想教一台计算机学习下棋,奖励信号如果是赢得游戏,那中间哪些动作步骤是正确的,仍然无法确定;即时奖励可以在计算机预测一步后,反馈出离最终奖励仍然有多少距离,比如胜率是否增加。
预测随时间的变化(时间差)提供强化信号,那么在下次计算机下棋时,就可以采取那些能增加胜率的动作。
破圈
2016年,一场围棋人机大战,让强化学习广为人知,连学术圈之外的人都能聊两句「阿尔法狗」。
Google DeepMind开发的AlphaGo,最终以四胜一败击败李世乭,赛后韩国棋院授予AlphaGo为荣誉九段。

2017年,AlphaGo Master以3:0的战绩,击败了世界排名第一的围棋棋手柯洁,从此人类棋手再无一人是机器的对手。
可以说,强化学习让「围棋」死了一半。
之前的机器学习方法主要是有监督学习和无监督学习,在有监督设置下,人工标注样本给机器进行学习,样本量有限,无法适应「围棋」这种特征空间很大的情况;而无监督学习则是自动提取出有效特征,以在数据中找到结构。
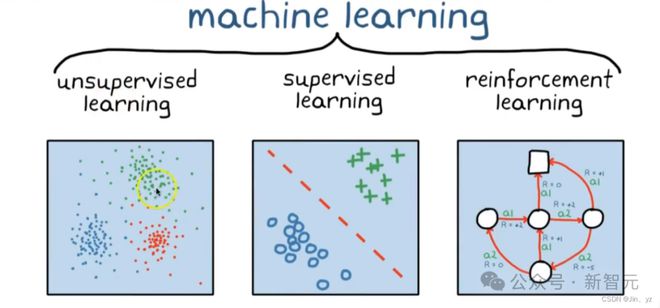
这两种方法在计算中都已被证明是有用的,但都不是生物大脑的学习方式。
强化学习的思路是,当神经网络实现了一个指定目标(比如赢得棋局)时,就会获得一定数值的奖励;如果失败了,会得到一个负值奖励。
机器可以通过不断试错来学习,尝试不同的移动,最终学到了在不同场景下应该使用哪种移动方式。
此后,强化学习一路高歌猛进,不仅攻克了各种电子竞技游戏,还引发了大型语言模型的推理革命,比如OpenAI o系列、DeepSeek-R1等推理模型,已成为新的研究主流。
人工智能的未来
Barto预测人工智能领域将向多智能体强化学习(multi-agent RL)方向演进,由神经网络社群及其个体奖励系统将形成互动,这种机制可能进一步催生出协作网络,多个模型为实现共同目标而互相奖励,也可能引发持有不同目标的智能体之间的利益冲突。
此类交互将对经济学与博弈论等复杂领域产生深远影响。
Sutton则认为人工智能发展仍处于初级阶段,包括向通用人工智能(AGI)的探索,即机器能理解人类认知范围内的所有事物,Sutton坚信强化学习将在这一进程中发挥关键作用。

谈到给年轻计算机研究人员的建议,Barton倡导效仿二人的科研路,勇敢追随自己的研究兴趣,不必在意领域内其他人的看法。虽然这很困难,但你必须找到内在驱动力,并尽你最大的能力坚持下去。
Sutton则给出更具体的建议,「坚持写作」,通过文字记录来锤炼思想。
一说起计算机科学的未来,Sutton就充满信心:未来几十年内,人类将彻底破解人工智能的奥秘!这有可能是史上最伟大的智力飞跃,能为其贡献绵薄之力是我们的荣幸。
参考资料:
https://cacm.acm.org/news/a-rewarding-line-of-work/
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/8465.html