


编辑:KingHZ 桃子
【导读】o3和o4-mini视觉推理突破,竟未引用他人成果?一名华盛顿大学博士生发出质疑,OpenAI研究人员对此回应:不存在。
在视觉感知方面,o3和o4-mini在思维链中进行图像推理, 代表了一个重要突破。
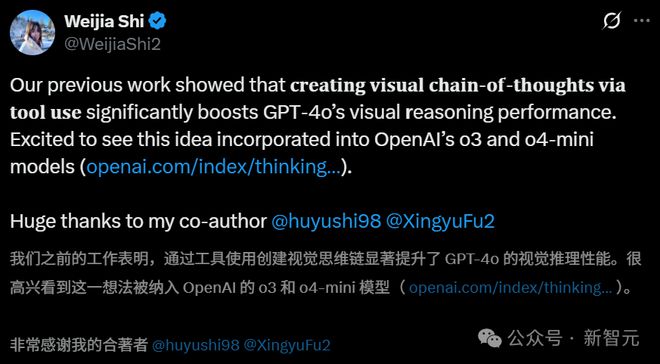
华盛顿大学计算机科学博士生施惟佳站出来表示,o3和o4-mini可能用到了她之前的研究Visual Sketchpad 。

论文链接:https://visualsketchpad.github.io/
这项发表于24年研究中,曾提出通过可视化辅助增强模型推理。一时间,这一猜测如同一石激起千层浪。
更猛烈的炮火来自滑铁卢大学CS助理教授、谷歌DeepMind高级研究科学家陈文虎。
他表示,「OpenAI既不承认也不引用任何相关工作。这真可悲。」

领导OpenAI感知团队的华人科学家Jiahui Yu表示:「确实不知道,但看起来很酷。」

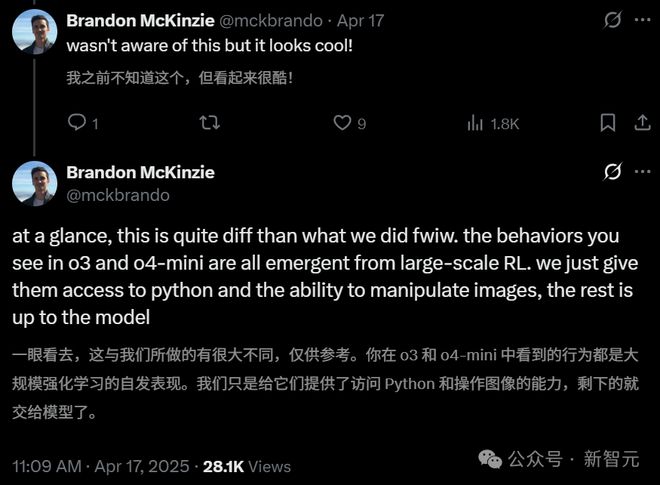
OpenAI的内部员工Brandon McKinzie表示,一眼看上去,与我们研究的有很大不同。而且o3和o4-mini行为都是自发的表现。
随后,这引发了关于o3视觉推理能力的大讨论。
但OpenAI陷入争议的不止是视觉推理,在数学基准测试中被爆出「作弊」!
视觉推理大辩论
首先登场的是Brandon McKinzie。
他瞥过一眼Visual Sketchpad,认为OpenAI的技术与之完全不同:
与我们之前做的事情完全不同,值得注意的是,o3和o4-mini中的行为完全是由大规模强化学习(RL)产生的。
我们只是给它们提供了访问Python和操作图像的能力,其余的都交给了模型自己去处理。
但华盛顿大学的博士生胡雨石(Yushi Hu),对此并不完全认同。
模型又是如何学会操作图像的?
他猜测到OpenAI可能使用了SFT数据,和谢赛宁V*论文或可视化草稿本论文类似。

此时,另一个华人AI大牛谢赛宁加入了辩论。
他提出了「用图思考」的更深入的思考。

谢赛宁:识别已死,视觉永生
关于「用图思考」的概念,谢赛宁有5点进一步的思考。

1. 零样本工具使用有局限性。
不能仅仅调用一个物体检测器就实现视觉搜索。
这也是为什么像VisProg、ViperGPT、Visual-sketchpad这样的方式难以泛化或扩展的原因。
它们更像是「外挂式工具调用」,而不是系统性能力。
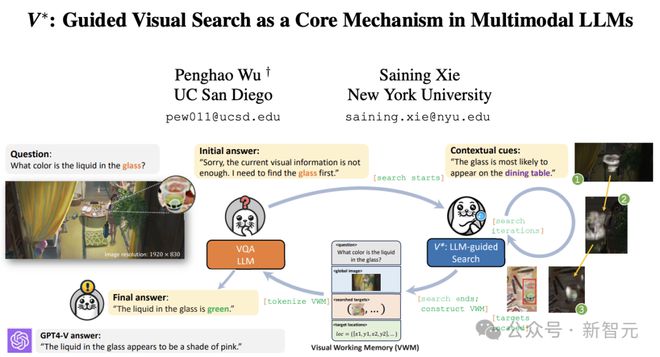
谢赛宁在V*项目中就专注于这一点,但两年前他还没有意识到强化学习(RL)会变得这么强大,因此只能依靠监督微调(SFT)来训练检测头。
这种方式虽然能跑通,但速度慢,训练过程也颇为痛苦。
论文链接:https://arxiv.org/abs/2312.14135
2. 视觉搜索必须是多模态大模型的原生组件,且要端到端整合。
3. 如果所使用的工具本身是简单、低层次的——比如基础的Python图像处理函数,而不是像Faster R-CNN 这样的大模型——它们就可以直接被整合进端到端系统。
一旦强化学习规模化,这些简单工具就能变成「视觉基元」(visual primitives),模型可以自由组合它们,从而构建出可扩展的视觉能力。
4. 大家应该继续发掘这些视觉基元。
它们绝不仅仅是图像处理函数,也应该包括对视频、三维数据的处理方式,未来的视觉系统需要构建在更广泛的「感知基础件」之上。
5. 谢赛宁认为大多数传统的视觉识别模型已经「过时」了。
正如Ross Girshick所说,它们本质上就是「解析器」(parsers)。但视觉本身没有死,反而比以往任何时候都更有生命力、更令人兴奋。

视觉识别模型已过时
此外,谢赛宁爆出了更大的消息:为OpenAI新模型「用图思考」奠定基础的Bowen Cheng、Ji Lin,的确与他讨论过多模态基础相关话题。
而谢赛宁的V*从GPT-4V的55%性能跃升至o3的95.7%。
看到一个艰难的基准测试被解决,他感到一种深深的满足感:
这意味着视觉搜索,正成为多模态模型推理的一个基本组成部分,就像视觉对人类的意义一样。
然而,他认为不要只是紧跟OpenAI的步伐。
学术界需要向前推进,构建那些不仅仅是眼下相关的东西,而是能够塑造未来的事物——
也许还能够启发像OpenAI这样的伟大公司。
V*证明学术界可以做到。
谢赛宁的推文停留在转发微软VP Nando de Freitas的推文:
强化学习并非一切……
类似的说法只是宣传。

这就是对OpenAI的Brandon McKinzie的「一切能力都从RL训练涌现」的一种委婉的反驳。
o3数学成绩仅为10%,评测结果再陷争议
除了图像推理,o3在数学基准的成绩单,也受到了外界质疑。
去年12月,OpenAI官宣o3时,声称模型在FrontierMath基准测试中正确率超25%。
当时,业内其他顶尖模型的得分普遍低于2%,o3的表现无疑令人瞩目。

然而,这一亮眼的成绩似乎只是OpenAI内部测试的「理想状态」。
OpenAI首席研究官Mark Chen在直播中称,「为o3配置激进的测试时计算(test-time compute)后,我们能把成绩提高到25%以上。」
显然,25%得分来自一个计算资源更强大的o3版本,也就是上周发布的满血版。
针对满血o3,创建FrontierMath基准的研究机构Epoch AI,发布了独立测试结果:o3得分仅为10%,远低于OpenAI声称最高成绩25%。

这并不意味着,OpenAI故意造假。
OpenAI去年12月公布的基准测试中,也给出了一个与Epoch实测一致的「下界得分」。
Epoch补充说,测试结果的差异可能源于以下原因:
-
OpenAI内部测试使用了更强大的框架,投入了更多测试时计算
-
测试所采用的FrontierMath数据集版本不同:OpenAI可能使用的是290题的frontiermath‑2025‑02‑28‑private;Epoch使用的是180题的frontiermath‑2024‑11‑26。
与此同时,ARC Prize基金会在X上发帖证实,预发布版o3与公开版并非同一模型,后者「专门为聊天/产品场景调校」。
他们还指出,目前发布的各档o3计算级别(compute tiers),都比跑基准时用的版本小。

一般而言,算力档位越高,基准成绩也会越好。
此外,OpenAI技术团队成员Wenda Zhou在上周一次直播中坦言,相较于去年12月,经过优化后的o3更适合现实世界的用例,更侧重于真实使用场景与推理速度。因此,它在基准测试上可能会出现一些「偏差」。
这样的成绩落差,引起了不少网友质疑。
但严格来说,问题并不在于o3的实际表现。OpenAI旗下的其他模型,如o3‑mini‑high和o4‑mini,在FrontierMath上的表现都优于o3。

而且,奥特曼表示,计划在未来几周推出更强大的o3‑pro。
这意味着,o3的基准测试争议更多地是「面子问题」,而非OpenAI技术短板。

不过,这再次提醒我们:AI基准测试的结果不能只看表面,尤其当数据来自一家急于推广服务的公司时。
基准测试,权威性何在?
其实,o3的风波并非是孤例。
科技大厂竞相推出新模型吸引眼球,「基准测试争议」在AI行业已屡见不鲜。
今年1月,Epoch还曾因在o3发布后,才披露得到了OpenAI资金支持而饱受批评。


还有最近一次的乌龙,Meta用「特供版」Llama 4去刷分登上了Chatbot Arena榜单TOP 2。

总而言之,基准测试「水分」已成为一个不可忽视的问题,关键在于每个人理性看待AI成绩单。
参考资料:
https://x.com/mckbrando/status/1912704921016869146
https://x.com/tanmay2099/status/1913573862027247871
https://x.com/sainingxie/status/1912723048949584198
https://x.com/WeijiaShi2/status/1912648237561049334
https://techcrunch.com/2025/04/20/openais-o3-ai-model-scores-lower-on-a-benchmark-than-the-company-initially-implied/
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/4945.html