


编辑:英智
【导读】采样多就一定准吗?研究人员用实验告诉你:是的,而且超乎想象!基于采样的搜索不仅能在并行处理中大展身手,还通过隐式扩展让验证更精准。
先让模型生成多个候选答案,再通过自我验证挑出「真金」。
基于采样的搜索在许多推理任务中表现优异,可关于它的扩展趋势,还有许多未解之谜。
随着采样数量的增加,模型的推理性能能否继续提升?这种简单的搜索范式能在多大程度上扩展?
来自谷歌和伯克利的华人研究员发现,随着采样数量和验证强度的增加,模型的推理性能有显着的提升。
论文链接:https://arxiv.org/abs/2502.01839
增加测试时计算的方法有很多。有些是通过强化学习,隐式地鼓励模型生成更长、更详细的回答;还有些是通过巧妙的提示,让模型更准确地思考。
在众多方法中,基于采样的搜索策略显得格外突出,生成多个候选答案,再从中挑选出最佳的那个。
这种方法可以和其他策略搭配使用,还特别适合并行处理。
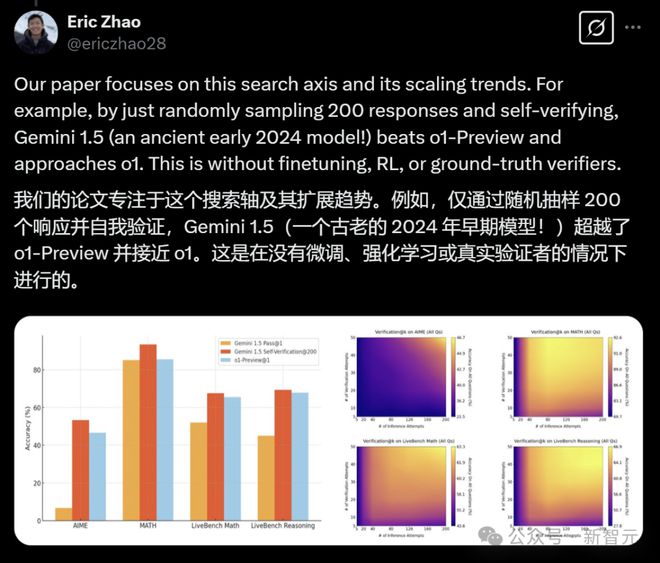
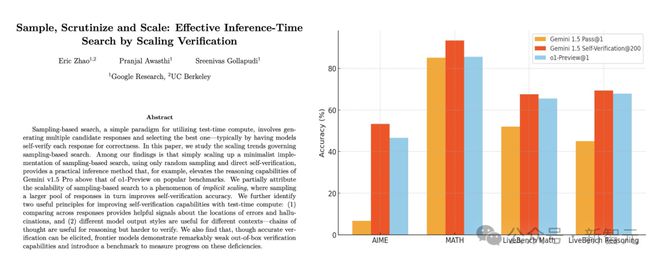
通过有效的自我验证,简单地扩展基于采样的搜索就足以在推理和数学基准测试,以及伯克利数学数据集上获得最先进的性能。
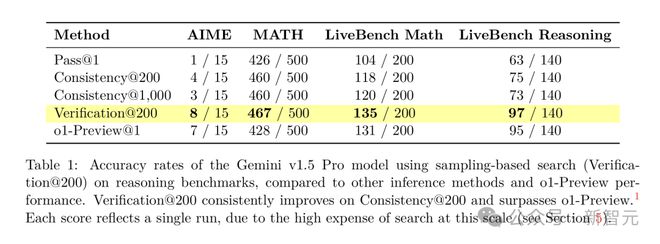
表中展示了Gemini v1.5 Pro模型在每个问题仅尝试一个解决方案(Pass@1)、尝试200个解决方案并选择最常见的最终答案(Consistency@200)以及在基于采样的搜索中尝试200个解决方案,并根据正确性评分选择得分最高的答案(Verification@200)时的准确性。
在基于采样的搜索(Verification@200)中,Gemini v1.5超越了o1-Preview。
基于采样的搜索
基于采样的搜索是怎么运作的呢?
简单来说,就是模型先通过随机采样的方式,生成一堆候选答案。
然后,模型再对这些候选答案进行自我验证,判断哪个答案最靠谱。
具体的实现过程可以分为几个关键步骤。首先是生成候选答案阶段,LLM会根据给定的问题,按照一定的温度参数(=1.5),并行生成个候选答案。
这个温度参数就像是调节模型创造力的旋钮,数值越大,生成的答案就越多样化,但也可能更偏离正确答案。
数值越小,答案就越保守,可能会错过一些有创意的解法。

接下来是验证候选答案阶段。模型会为每个候选答案生成个二进制的验证分数,以此来判断答案的正确性。
在这个过程中,模型会把答案改写为定理、引理和证明的形式,就像我们在数学证明中那样,一步一步严谨地检查答案是否合理。
要是遇到几个候选答案得分很接近的情况,模型会把这些答案两两比较,每次比较都会重复多次(=100次),最后选出获胜次数最多的答案作为最终输出。
扩展趋势
研究人员在探索基于采样的搜索的扩展趋势时,发现了一些有趣的现象。
他们通过实验,观察随着搜索,也就是采样的数量和验证次数这两个关键因素的变化,模型的推理性能会发生什么变化。
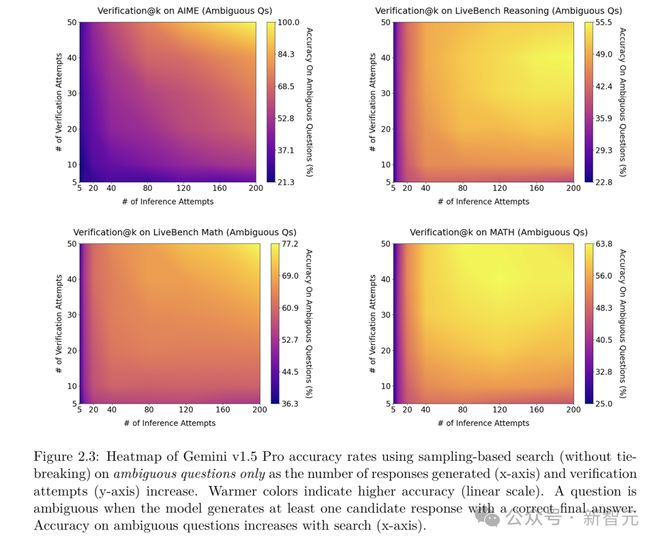
从实验结果的热图中可以看出,当搜索和验证同时扩展时,模型的性能提升最为明显。
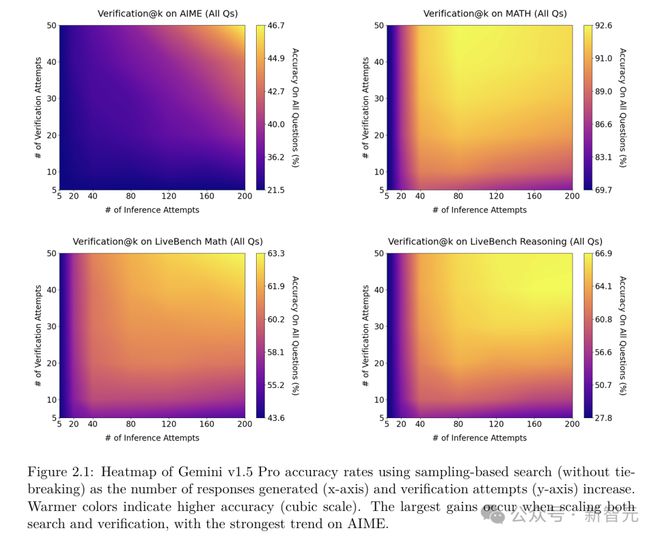
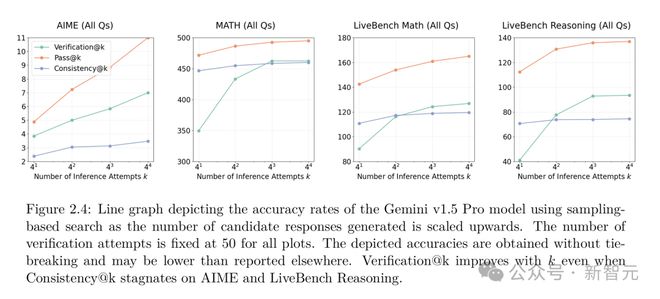
在一些基准测试中,比如AIME,即使测试时计算扩展到了自一致性方法性能饱和的程度,基于采样的搜索的推理性能仍然在持续提高。
在AIME基准测试中,基于采样的搜索的扩展趋势最为显着。
随着采样数量的增加,模型就能更大概率地找到正确答案。
而且,即使一致性方法(Consistency@k )在处理这些难题时已经达到了极限,基于采样的搜索(Verification@k )仍然能通过不断扩展验证能力,挖掘出那些隐藏在长尾中的正确答案。
研究人员还发现了一个很神奇的现象:隐式扩展。
按照常规想法,采样的答案越多,验证器要处理的信息就越多,验证的准确性应该会下降。但实际情况却恰恰相反!
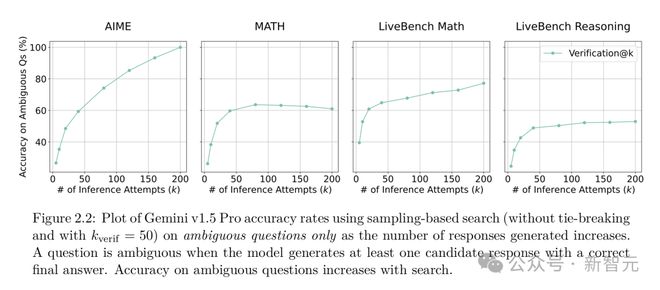
当模型生成的答案数量增加时,验证的准确性也跟着提高了。这是为什么呢?
原来,写得好的答案更容易被验证,而增加采样数量就像是扩大了答案的「海选范围」,让更多高质量的答案有机会被选出来。
在下图中,将验证尝试次数固定为50后,Verification@k的扩展超越了Consistency@k的饱和点。
在AIME基准测试里,Consistency@k趋于平稳,Verification@k却呈幂律扩展。在AIME上,Consistency@50和 Consistency@10,000准确率相同。
2024年AIME考试第二场第11题,Gemini v1.5模型从200个随机采样解决方案中,难以选定正确答案。
Consistency返回错误答案1,且该答案在超一半的响应中出现,而Verification成功从响应分布长尾中识别出正确答案601,并对1和601分别给出了≤36%和98%的分数。
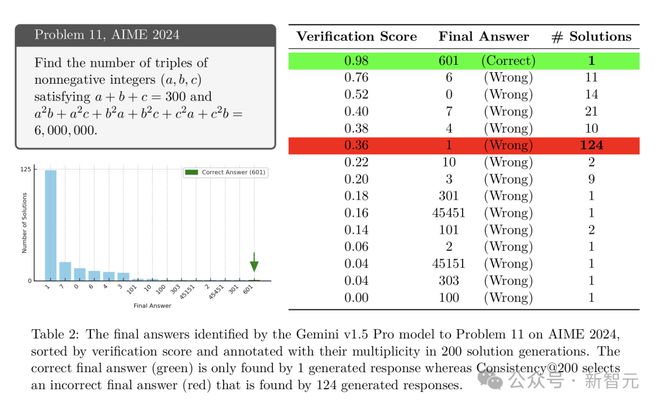
扩展验证能力是推动搜索改进的关键,可以区分不同置信度的答案。
验证能有效利用模型响应分布长尾,表明Pass@k应是搜索应用的关键性能指标,而现有针对Pass@1优化的训练后技术(如RLHF),可能牺牲Pass@k,抑制搜索能力。
有效自我验证:提升推理的法宝
研究人员还总结出了两个提升LLM自我验证能力的重要原则。
第一个原则是对比答案以定位错误。
LLM在识别错误和幻觉方面一直不太擅长,就像一个视力不太好的人,很难发现远处的小错误。但是,如果把不同的候选答案放在一起比较,模型就能更容易地发现错误的位置。
这种比较的方法,其实也是隐式扩展的一种体现,通过提供更多的对比信息,帮助模型更好地判断答案的正确性。
第二个原则是根据输出风格适用性改写答案。不同的任务需要不同风格的答案。
在生成答案时,思维链的方式很有效,它能帮助模型理清思路,找到正确的方向。
但这种方式生成的答案往往比较冗长复杂,验证起来难度较大。
相反,严谨、分层和模块化的写作风格虽然在生成答案时可能不太灵活,但在验证时却更容易被模型理解和判断。
所以,研究人员建议在验证答案时,先把答案改写成更规范的形式,比如像数学证明一样,有定理、引理和证明过程,这样模型就能更轻松地检查答案是否正确了。
为了验证这两个原则的有效性,研究人员还进行了消融研究。他们分别去掉比较答案和改写答案这两个操作,看看会对模型的性能产生什么影响。
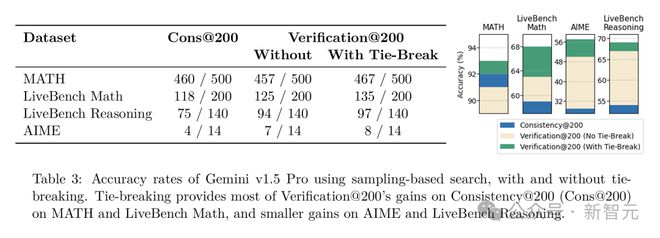
结果发现,去掉比较答案的操作后,模型在一些基准测试中的性能明显下降。去掉改写答案的操作后,验证的准确性也受到了很大影响。
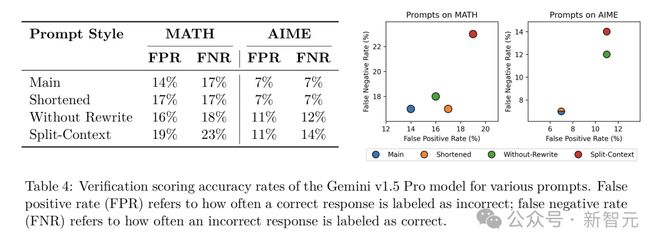
这充分说明了这两个原则对于提升模型自我验证能力的重要性。
额外实验,探索更多可能
研究人员还进行了一些额外的实验,为我们揭示了更多有趣的发现。
在对较小模型的研究中,他们发现基于采样的搜索同样能为这些「小个子」模型带来显着的性能提升。
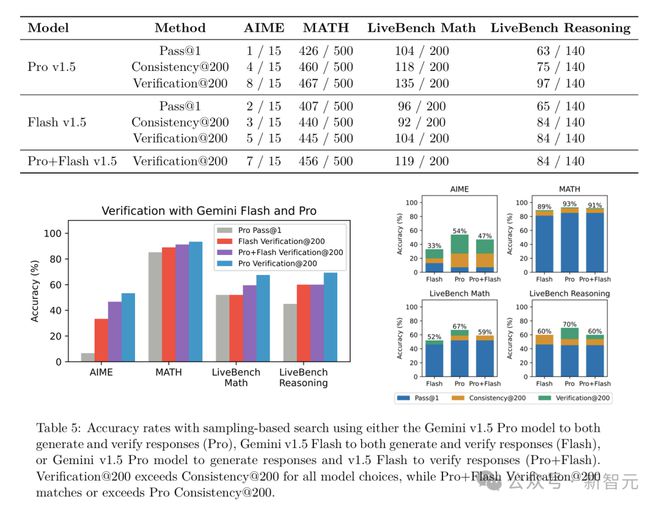
以Gemini v1.5 Flash模型为例,它的推理成本比Gemini v1.5 Pro低很多,但通过基于采样的搜索,它的性能得到了大幅提升。
即使是用Flash模型来辅助Pro模型进行验证(Pro+Flash),也能取得不错的效果,甚至在某些情况下,Pro+Flash Verification@200的性能超过了Pro Consistency@200。
研究人员还对LiveBench基准测试中的不同子任务进行了分析。
他们发现,基于采样的搜索在不同子任务上的表现各有差异。
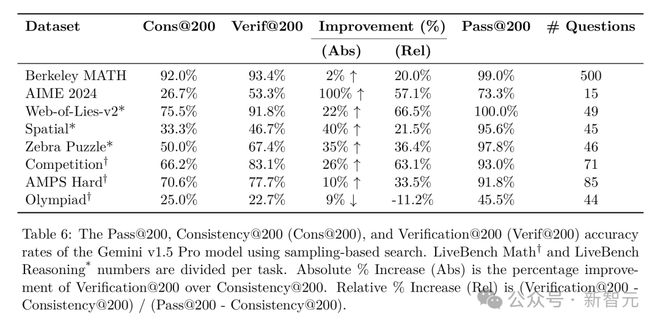
在AIME 2024、Web-of-Lies、Competition和Zebra Puzzle等任务上,Verification的提升效果非常明显;但在LiveBench Math的Olympiad任务上,却没有看到明显的提升。
这是因为Olympiad任务的问题设计比较特殊,它要求填写预写证明中的表达式选项,输出特定的索引序列。
衡量模型的新验证基准
前沿LLM虽然在解决问题方面表现得很厉害,但它们的开箱即用验证能力却有点拖后腿。
为了更准确地衡量这个问题,研究人员创建了一个新的验证基准。
这个基准里包含了很多具有挑战性的推理问题,每个问题都有一个正确答案和一个错误答案。


基准测试主要关注两个任务:评分任务和比较任务。
在评分任务中,模型要判断给定答案是否正确;在比较任务中,模型要从两个答案中找出正确的那个。
这就好比让模型当小老师,批改作业和比较不同学生的答案。
研究人员用这个基准测试了一些当前的模型,结果发现表现参差不齐。
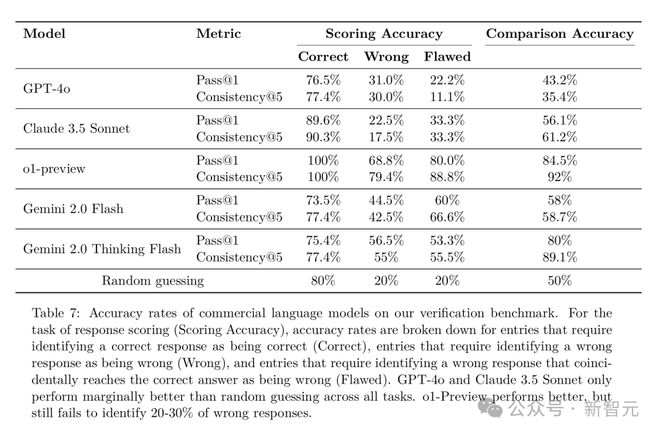
有些模型在验证方面的表现甚至比随机猜测好不了多少,这说明它们在识别错误答案和判断答案正确性方面还有很大的提升空间。
基于采样的搜索展现出了巨大的潜力。
它不仅简单有效,而且具有很强的扩展性,能在各种推理任务中发挥重要作用。
参考资料:
https://x.com/ericzhao28/status/1901704344506192365
https://techcrunch.com/2025/03/19/researchers-say-theyve-discovered-a-new-method-of-scaling-up-ai-but-theres-reason-to-be-skeptical/
https://eric-zhao.com/blog/sampling
https://arxiv.org/abs/2502.01839
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/4927.html