


编辑:英智
【导读】研究揭示早融合架构在低计算预算下表现更优,训练效率更高。混合专家(MoE)技术让模型动态适应不同模态,显着提升性能,堪称多模态模型的秘密武器。
如今,打造强大的多模态模型是AI领域的重要目标。
一种常用方法是把单独预训练好的模型组合起来,比如把训练好的视觉编码器连接到LLM的输入层,再进行多模态训练。
然而,单模态预训练可能会带来一些偏差,影响模型对不同模态之间相互依赖关系的学习。
且每个单模态组件都有自己的超参数、预训练数据和缩放属性,给系统扩展增加了不少难度。
研究人员把希望寄托在了原生多模态模型(NMM)上,NMM是在所有模态上同时从头开始训练的。
这种全新的训练方式能不能突破现有的困境,让模型性能更上一层楼呢?
来自法国索邦大学、苹果的研究人员开展了原生多模态Scaling Laws的研究,表明早融合优于后融合,多模态MoE好于密集模型。

论文链接:https://arxiv.org/abs/2504.07951
研究表明,后融合架构相较于不依赖图像编码器的早融合架构,并没有固有优势。
早融合架构在参数数量较少时,性能更强,训练效率更高,部署起来也更容易。
引入混合专家(MoE)技术,能让模型学到特定模态的权重,进而大幅提升性能。
研究成果总结如下:
原生早融合与后融合性能相当:从零开始训练的早融合模型与后融合模型性能相当,在计算预算较低时,早融合模型略有优势。

此外,Scaling Law研究表明,随着计算预算的增加,早融合和后融合的计算最优模型性能相似(图1-左)。
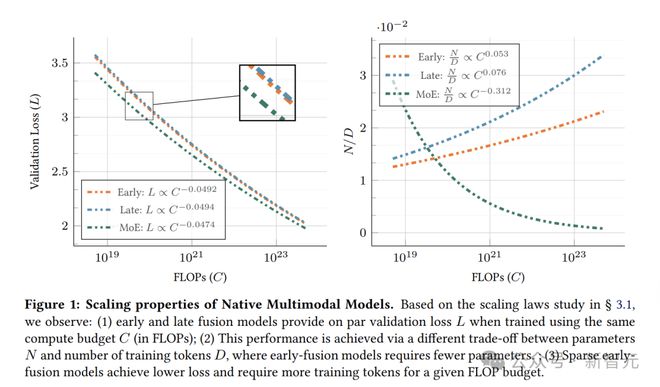
原生多模态模型(NMM)Scaling Law与LLM相似:原生多模态模型的扩展规律与纯文本LLM相似,扩展指数因目标数据类型和训练混合比例略有变化。
后融合需要更多参数:与早融合相比,计算最优的后融合模型需要更高的参数-数据比(图1-右)。
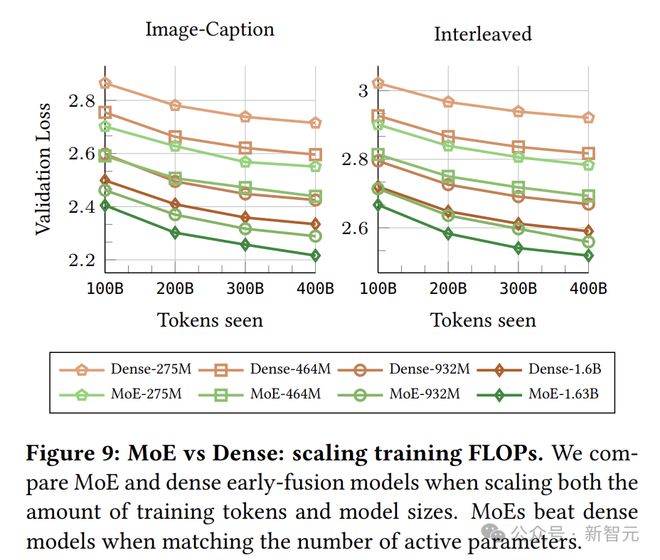
稀疏性显着提升早融合NMM性能:在相同推理成本下,稀疏NMM相较于密集模型有显着改进。
此外,稀疏训练的模型会隐式学习模态特定权重。
随着计算预算增加,计算最优模型更依赖于增加训练token数量,而非活跃参数数量(图1-右)。
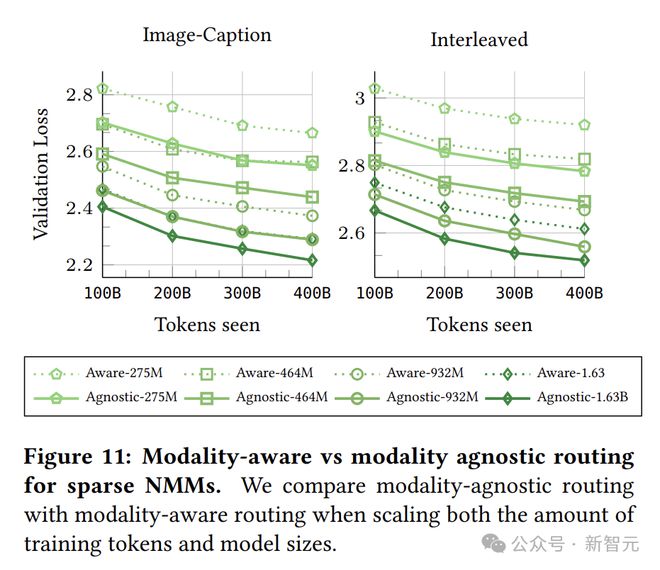
对于稀疏NMM,模态无关路由优于模态感知路由:在稀疏专家混合模型中,使用模态无关路由训练的性能始终优于采用模态感知路由的模型。
原生多模态Scaling Law
为深入了解原生多模态模型的性能表现,研究人员引入了Scaling Law的概念。
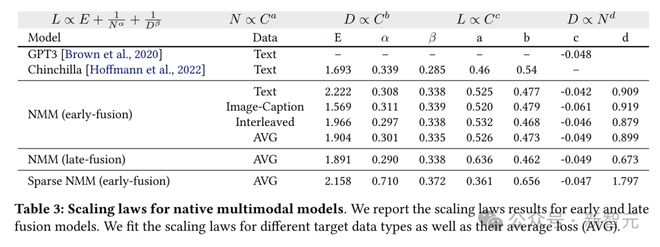
通过计算模型的浮点运算次数(FLOPs)来衡量计算量的大小,并且假设模型最终的损失和模型的大小(用参数数量N来表示)以及训练token的数量(D)之间存在一种幂律关系:
E代表在数据集上可达到的最低损失,表示增加模型参数数量对损失的影响,一般来说,模型参数越多,损失就会越低,α是控制这种变化速度的,体现了增加训练token数量带来的好处,β决定了其增长速度。
同时,研究人员还发现计算预算(FLOPs)和N、D之间存在线性关系。
早融合和后融合模型的Scaling Law。
图2(左)呈现了早融合的NMM在多模态交织、图像-描述以及文本这三类数据集上的平均最终损失。
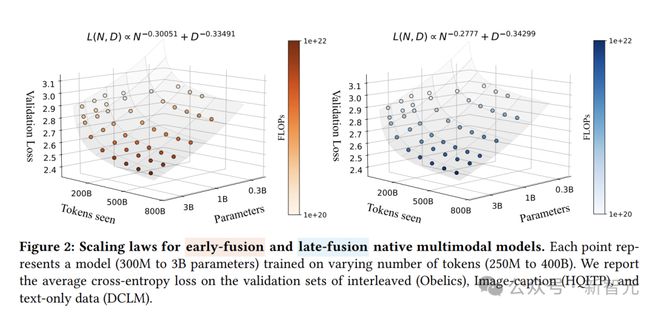
可以看到,其最低损失的变化趋势遵循着与浮点运算次数(FLOPs)相关的幂律关系。通过对这一规律进行拟合,得到表达式
反映出随着计算量的增加,模型性能提升的速度。
在分析不同数据类型(如图像字幕、交错、文本)时,观察到指数有所不同。

与交错文档相比,模型在图像字幕数据上实现了更高的性能提升速率。
图2(右)后融合模型中,观察到损失Scaling指数与早融合几乎相同。
研究人员采用了457个具有不同架构和训练混合方式的训练模型,模型的参数量从0.3B到4B。
他们还调整了训练token的数量,同时改变训练数据的混合方式,以此来全面探究各种因素对模型性能的影响。
研究人员采用了自回归Transformer架构,搭配SwiGLU前馈网络和QK-Norm技术,还使用了像bfloat16、全分片数据并行(FSDP)、激活检查点和梯度累积等多种优化方法,让训练更高效。
早融合优势尽显
在低计算预算(模型规模较小)的情况下,早融合模型略胜一筹。
随着计算预算的增加,虽然两种模型的性能逐渐接近,但早融合模型在训练效率上具有明显优势。
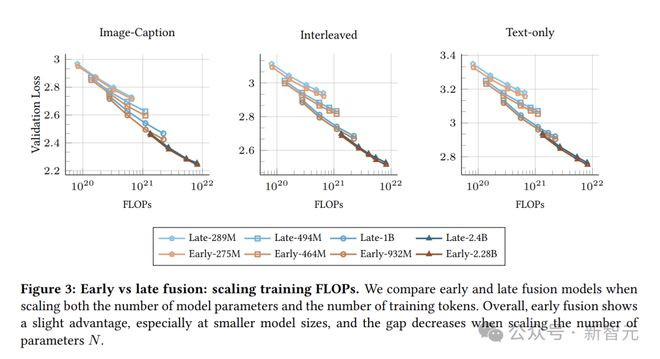
对比NMM和仅基于文本的LLM(如GPT-3、Chinchilla)的Scaling Law系数,会发现它们处于相似范围。
早融合与后融合NMM的计算最优权衡。虽然后融合和早融合模型随着FLOPs增加,损失降低的速度相近。
在缩放FLOPs时,早融合模型的参数数量明显更少,这对降低推理成本很关键,部署后也能降低服务成本。
在计算资源相同的情况下,早融合模型不仅占用的内存更少,训练速度也更快。
当计算量增大时,这种优势愈发显着。这说明早融合在保持相当的大规模训练时性能时,还具备超高的训练效率。
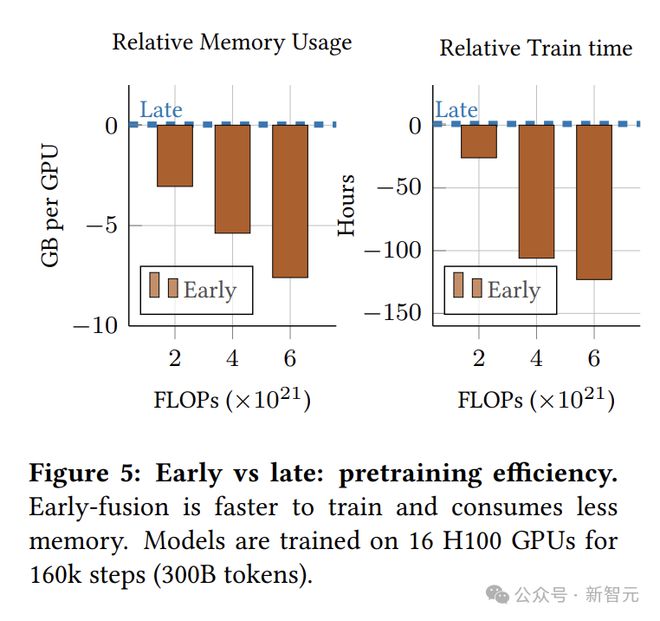
值得注意,在相同的FLOPs下,与早融合模型相比,后融合模型具有更高的参数量和有效深度。
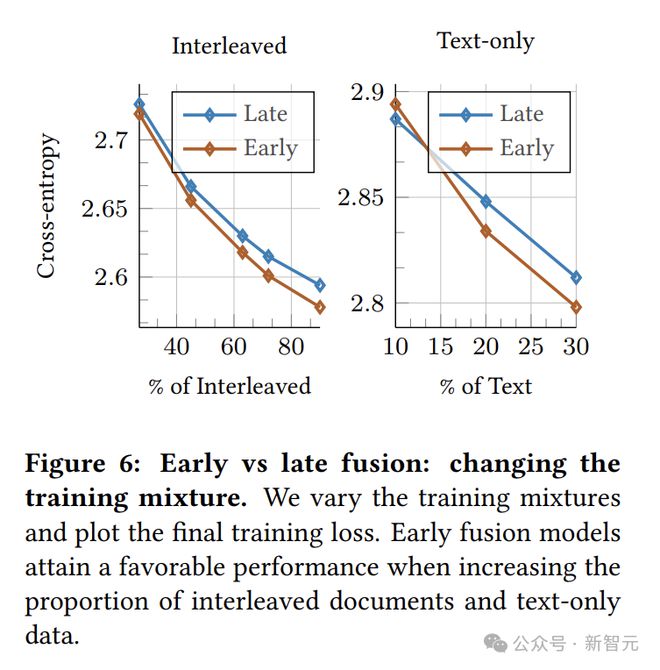
不同数据混合的Scaling Law
图4表明不同的数据混合方式在模型训练中呈现出相似的缩放趋势,不过它们的缩放系数存在差异(表4)。
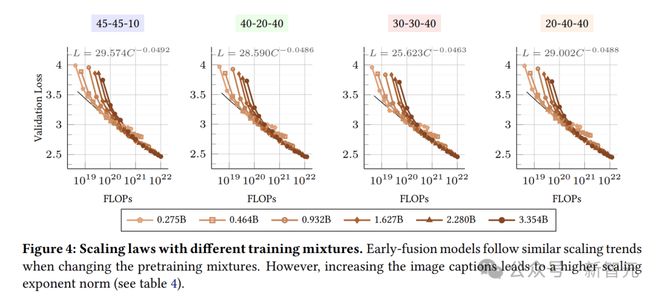
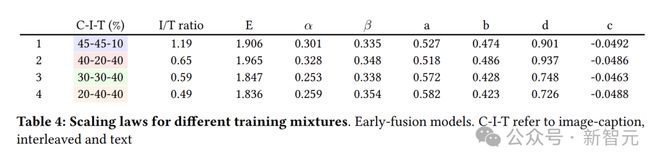
有趣的是,增加图像字幕数据的比例(混合方式1和2)会导致a值降低和b值升高,而增加交错和文本数据的比例(混合方式3和4)会产生相反的效果。
图像说明数据中,图像token占比高于文本token。因此,提高图像说明数据的比例会增加图像token数量,而增加多模态交织数据或文本数据的比例则会提升文本token数量。
这表明,当图像token占主导时,训练时间越长,损失下降越快,增加模型规模会进一步加速这一过程。
对于固定的模型大小,增加纯文本和交错数据的比例有利于早融合模型。
原生多模态预训练与LLM的持续训练
对比两种训练方式:一种是从头开始进行原生训练,另一种是先用预训练的LLM进行初始化,再持续训练。
实验用的初始模型是DCLM-1B,它在超过2T个token的数据上完成了训练。
随着训练时间的延长,NMM和经过初始化的模型之间的差距会逐渐缩小。
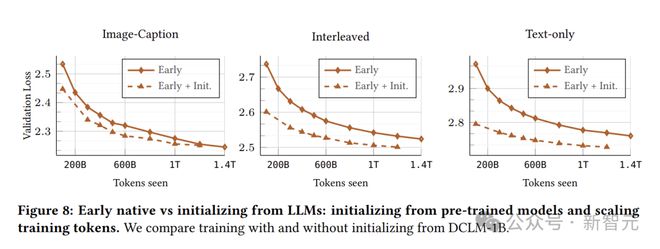
具体来说,在图像字幕数据上,模型需要不到100B个多模态token就能达到可比的性能。
然而,在交错和文本数据上,模型可能需要更长的训练时间(多达1T token)。
考虑到预训练的成本,为了实现相同的性能,原生多模态训练可能是更有效的方法。
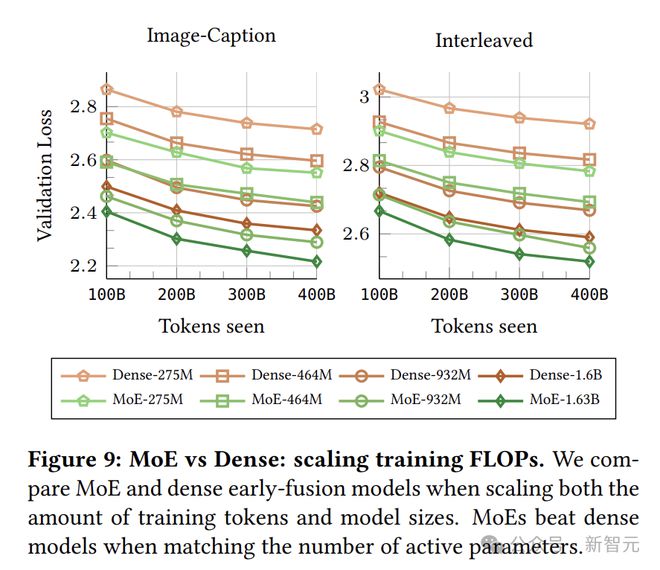
多模态专业化:MoE的妙用
早融合模型在很多方面表现出色,但多模态数据的异构性仍然是一个挑战。
为了让模型更好地处理这种异构数据,研究人员引入了专家混合(MoE)技术。
MoE技术允许模型在不同模态之间动态分配专门的参数,以更好地适应多模态数据的特点。
实验结果显示,在相同推理成本下,MoE模型的表现明显好于密集模型,尤其是在模型较小时,优势更为明显。
这说明MoE架构在处理异构数据时更高效,还能针对不同模态进行专门处理。
为了验证前面通过验证损失得到的结论在实际应用中的有效性,研究人员在下游任务上进行了评估。
他们在LLaVA混合数据上进行了多模态指令调整阶段(SFT),并在多个视觉问答(VQA)和图像字幕任务中测试了模型的性能。
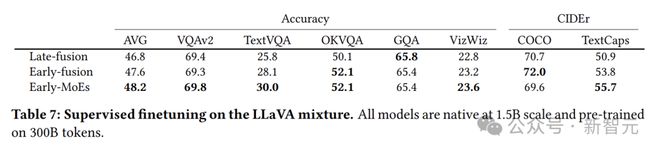
结果再次证实了之前的发现:早融合模型优于后融合模型,采用MoE的模型优于密集模型。
不过,由于实验中的模型相对较小(1.5B),并且是从头开始训练并在小数据集上微调,总体分数与当前最先进的模型还有一定差距。
但这也为后续的研究指明了方向,即通过进一步优化模型规模、训练数据和微调策略,有望提升模型在实际任务中的表现。
参考资料:
https://www.alphaxiv.org/overview/2504.07951
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/7328.html