


编辑:犀牛
【导读】来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。
大语言模型(LLM)在文本和多模态任务上已经展现出惊艳的表现。
像是最新的Gemini 2.5 Pro在文本及代码上的顶尖性能,以及GPT-4o的原生生图能力都很好的证明了这点。
然而,很多实际应用场景,比如长文档和视频理解、上下文学习以及推理时扩展,都需要模型能够处理超长的token序列。
在这些场景中,模型的上下文窗口受限往往成为一大瓶颈,因为分布在长文档中的关键信息可能会被忽略。
为了解决这些问题,来自英伟达和UIUC的研究者提出了一种高效的训练方法。
这种方法可以从现有的指令微调模型出发,构建超长上下文的LLM,最高可将上下文长度推向400万token的极限!

论文地址:https://arxiv.org/pdf/2504.06214
研究人员利用上面方法训练的UltraLong-8B模型在长上下文任务上达到了顶尖水平,同时在标准任务上也保持了竞争力。
主要贡献:
-
高效且可扩展的训练方法。
-
关键技术创新:研究者引入了特殊文档分隔符和基于YaRN的位置编码扩展技术,通过消融实验证明这些技术对长上下文建模至关重要。
-
高效的单步预训练策略:研究者发现,相比多步扩展方法,单步持续预训练在上下文扩展上更高效,在合成和真实世界长上下文基准测试中始终表现出色。
-
全面的实验验证:研究者在多个基准测试上进行了广泛实验,包括RULER、LV-Eval、InfiniteBench、MMLU、MMLU-Pro、MATH、GSM-8K和HumanEval,证明UltraLong-8B模型在长上下文和标准任务上均优于现有基线。
实验方法
如图1所示,本文方法主要分为两个阶段:持续预训练和指令微调。
以Llama 3.1-8B-Instruct为基础,持续预训练阶段将模型的上下文窗口逐步扩展到目标长度(比如100万、200万、400万token)。随后,指令微调阶段优化模型的指令遵循能力和推理能力。
这两个阶段结合,让模型既能高效处理超长输入,又能在长短上下文任务中表现出色。
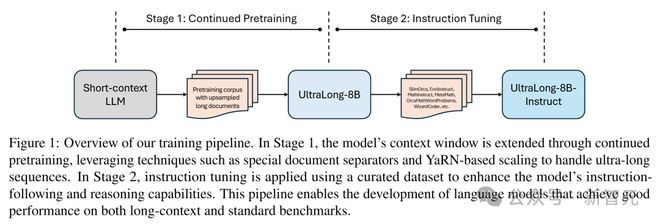
第一阶段通过持续预训练扩展模型的上下文窗口,采用特殊文档分隔符和基于YaRN的缩放技术来处理超长序列。第二阶段使用精心挑选的数据集进行指令微调,提升模型的指令遵循和推理能力
持续预训练:扩展上下文长度
在第一阶段,研究者通过持续预训练将Llama-3.1-8B-Instruct的上下文窗口扩展到目标长度。
研究者对少于4000 token的短文档进行下采样,对超过8000 token的长文档进行上采样,最终形成一个包含10亿token的语料库。
这些文档被拼接成对应目标上下文长度的更长序列(比如100万、200万、400万token)。拼接时,他们使用特殊字符分隔不同文档,而不是用保留的开始和结束标记。
此外,在持续预训练中,研究人员没有使用跨文档注意力掩码,从而允许模型关注整个输入序列。
为了支持超长上下文,研究人员采用了基于YaRN的缩放方法,而不是之前工作中常用的NTK感知缩放策略。他们固定超参数α=1和β=4,并根据目标上下文长度计算缩放因子s。
当输入长度接近最大限制时,Llama-3.1模型的性能会下降。为解决这个问题,他们为RoPE嵌入采用了更大的缩放因子,从而更好地适应超长序列。
研究者针对三种上下文长度(100万、200万和400万token)构建了长上下文模型,并将RoPE缩放因子分别设置为128、256和512。
每个模型在10亿token的语料上训练一个epoch,学习率为3×10⁻⁵。
为了提升训练的可扩展性,他们使用了Megatron-LM框架。为了处理超长输入序列,采用了张量并行和上下文并行。
训练在256个NVIDIA H100 GPU上进行,1M、2M和4M模型的训练时间分别约为5小时、6小时和13小时。
指令微调
在第二阶段,研究者通过监督微调(SFT)提升长上下文模型的指令遵循和推理能力,使用的是一些精心挑选的数据集。
他们整合并优化了多个开源SFT数据集,覆盖三个关键领域:通用领域、数学和代码。
为了进一步提升SFT数据集的质量,他们利用GPT-4o和4o-mini优化了这些数据集的回答内容。
值得注意的是,研究者的SFT数据集仅包含上述短上下文数据(少于8000 token的样本),没有加入合成长上下文指令数据。
他们发现,仅依靠短上下文数据就足以取得优异效果,这与之前研究的观察一致。
最终,研究者构建了一个包含10万个样本的SFT数据集。对于每种目标上下文长度的模型,他们使用128的批大小和5×10⁻⁶的学习率。
训练依然基于Megatron-LM 框架,在256个NVIDIA H100 GPU上进行,张量并行度设为tp=8。每次训练大约需要 30 分钟。
基线模型与评估基准
研究者将他们的模型与基于Llama家族的最先进(SOTA)长上下文模型进行对比,以确保对训练方法公平且可控的评估。
-
Llama-3.1 (Llama-3.1-8B-Instruct):这是他们的基础模型,支持128K的上下文窗口。
-
ProLong (Llama-3-8B-ProLong-512k-Instruct):基于Llama-3构建的长上下文模型,拥有512K的上下文窗口。
-
Gradient (Llama-3-8B-Instruct-Gradient-1048k):另一个基于Llama的长上下文模型,支持高达1M的上下文窗口。
本文研究者专注于Llama家族的模型,这样可以更清晰地展示他们扩展上下文长度训练方法的有效性,同时确保在标准任务上的性能依然具有竞争力。
他们通过以下基准测试来评估模型的长上下文能力:
-
RULER:这是一个专门评估长上下文语言模型的基准,通过生成不同序列长度的合成样本,覆盖四个任务类别。
-
LV-Eval:这是一个长上下文基准,包含最高256K token的五个长度级别,重点测试两种任务:单跳问答(single-hop QA)和多跳问答(multi-hop QA)。
-
InfiniteBench:这是一个长上下文基准,平均输入长度约200K token,最大长度超过2M token,包含合成任务和现实世界任务。
实验结果
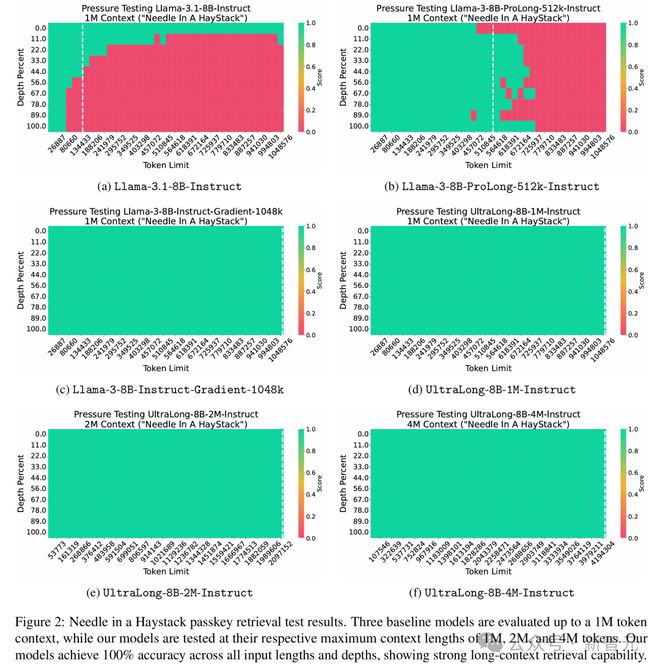
研究人员首先从「大海捞针」(Needle in a Haystack,NIAH)这一测试开始,然后再探讨长上下文和标准基准的评估。
研究人员通过NIAH密码检索测试,评估模型在长上下文检索方面的能力。在这个任务中,模型需要在一大段毫无意义的文本中,找到一个简单密码,比如一个随机的六位数字。
为了量化检索的准确性,他们测试了40种不同的输入序列长度。对于每种长度,密码会被随机插入到10个均匀分布的文档深度中。
结果如图2所示。对于本文的模型,测试了高达100万、200万和400万个token的输入长度;而对于基准模型,只测试了最高100万个token。
如图2a到2c所示,在基准模型中,只有Llama-3-8B-Instruct和Gradient-1048k通过了NIAH测试,而Llama-3.1-8B-Instruct和Llama-3-8B-ProLong-512k-Instruct即使在它们声称的上下文长度内也出现了错误。
相比之下,如图2d到2f所示,研究者的超长(UltraLong)模型在所有输入长度和深度上都达到了100%的准确率,展现了强大的长上下文检索能力。
研究者在RULER、LV-Eval和InfiniteBench上的评估结果如表1所示。加粗的数字表示性能超过了所有基准模型。
总体来说,他们的三个模型在大多数情况下都取得了最高分。
在RULER基准测试中,UltraLong模型在512K和100万个token的输入长度上表现最佳。在LV-Eval中,他们的模型在128K和256K token长度内的平均F1分数最高。
此外,他们在InfiniteBench上也取得了最佳表现。
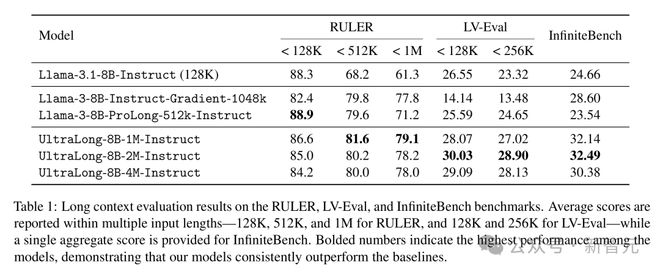
这些结果表明,研究者的训练方法有效扩展了语言模型的上下文窗口到超长输入,同时保持了原有输入长度的性能。
相比之下,基准模型中,Llama-3.1是为128K输入长度设计的,当输入超过128K token时,性能显着下降。ProLong是为512K上下文设计的,但即使它训练了更多token(410亿对比10亿),在512K长度上的表现也不如他们的模型。
Gradient是基准模型中支持最长上下文的(100万个token),但在LV-Eval和InfiniteBench上的表现较差,说明它的设计可能过于偏向人工任务,牺牲了现实任务的效果。
而本文的模型在人工(RULER)和混合(LV-Eval和InfiniteBench)基准测试中始终保持更高的分数,凸显了方法的高效性和可扩展性。
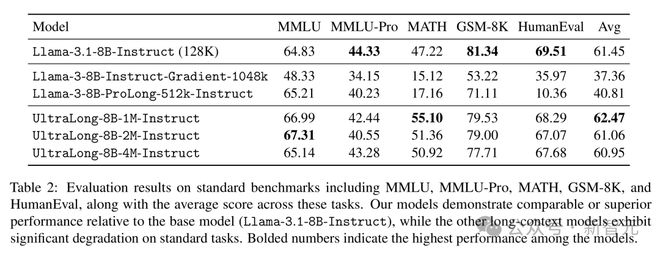
研究者还通过通用、数学和代码领域的标准基准测试评估了模型,以确保扩展上下文长度不会影响短上下文任务的性能。
如表2所示,他们的模型性能与基础模型Llama-3.1-8B-Instruct相当甚至更高,平均分数分别为62.47、61.06和60.95,而Llama-3.1-8B-Instruct为61.45。
特别值得一提的是,他们的模型在MMLU和MATH基准上表现出明显提升,同时在GSM8K和HumanEval等其他基准上的表现也极具竞争力。
相比之下,基准长上下文模型Gradient和ProLong在这些标准任务上的性能大幅下降,平均分数仅为37.36和40.81。
这些结果表明,研究者的方法不仅有效扩展了上下文窗口,还保持甚至提升了模型的通用任务能力。
而Llama-3-8B-Instruct-Gradient-1048k和Llama-3-8B-ProLong-512k-Instruct的显着性能下降,表明它们的超长上下文方法可能存在局限性。
结论
在这项工作中,研究人员提出了一种高效且系统化的训练方法,用于超长上下文语言模型,将上下文窗口扩展到100万、200万和400万个token,同时在标准基准测试中保持了竞争力。
这种结合了高效的持续预训练和指令微调,不仅提升了模型对长上下文的理解能力,还增强了其遵循指令的能力。
这一框架为可扩展的长上下文建模树立了新标杆,也为未来在实际应用中提升长上下文性能的研究铺平了道路。
作者介绍
Chejian Xu

伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学博士研究生,导师是Bo Li教授。浙江大学计算机科学与技术专业学士学位,就读于CKC荣誉学院,导师是Shouling Ji教授和Siliang Tang教授。
专注于提升基础模型的安全性、可靠性和一致性,包括LLMs、多模态模型以及基于LLM的智能体。
Wei Ping

NVIDIA应用深度学习研究团队的资深研究科学家,专注于大型语言模型和生成模型的研究。
加州大学欧文分校机器学习博士学位,热衷于构建用于文本、音频和多模态数据的尖端生成模型。此前,曾担任百度硅谷人工智能实验室(由吴恩达创立)的文本到语音团队负责人。
参考资料:
https://arxiv.org/abs/2504.06214
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/6824.html