


编辑:KingHZ
【导读】南加州大学团队只用9美元,就能在数学基准测试AIME 24上实现超过20%的推理性能提升,效果好得离谱!而其核心技术只需LoRA+强化学习,用极简路径实现超高性价比后训练。
只用9美元,在数学基准测试AIME 24上,实现了超过20%的推理性能提升!
来自南加州大学(University of Southern California,USC)的研究团队,基于LoRA的强化学习(RL)训练了1.5B推理模型——
这种极简的方法训练出的模型不仅能与当前最先进的强化学习推理模型相媲美,有时甚至超越它们,即便它们是基于相同底座模型构建的。

论文链接:https://arxiv.org/abs/2504.15777
在AIME 24推理任务中,最好的新模型实现了超过20%的性能提升,达到了43%的Pass@1准确率,而训练和评估的总成本仅为9美元!
在X上,19岁获得博士学位、AI初创的CEO「少年天才」Tanishq Mathew Abraham推荐了此论文,已有数万浏览。

X用户Omar则表示:新方法令人激动,是金融科技的灯塔!完美契合金融科技的增长需求!
Tina:利用LoRA的微型推理模型
开源的微型推理模型Tina算法系列,结合了三大关键技术。
-
强大而轻量级的基础模型:所有的Tina模型都基于DeepSeek-R1-Distill-Qwen-1.5B构建而成,在极小的计算资源占用下展现出色能力。
-
参数高效后训练微调(Parameter-efficient post-training):在强化学习(RL)阶段,采用低秩适应(LoRA)技术,显着降低了计算成本,同时不减推理性能。实际上,与全参数微调相比,有时甚至能提升模型的推理性能!
-
精选的数据集:在精简而高质量的数据集上,全部Tina模型都进行后训练微调,进一步降低了整个流程的计算复杂度。
开源推理模型时间线:开源「推理复制品」(reasonging replicas)旨在复现高级推理模型的性能
效果好得邪门!
与使用相同基础模型的SOTA模型对比,Tina模型不仅具备竞争力,有时甚至还能超越它们——
而所需成本却只是它们的零头!
简单来说,就是:更少的算力,带来了更高的性能!
下图1展示了Tina模型最佳checkpoint和基准模型的比较结果,其中推理性能(reasoning performance)表示在AIME24/25、AMC23、MATH500、GPQA和Minerva上的平均得分。
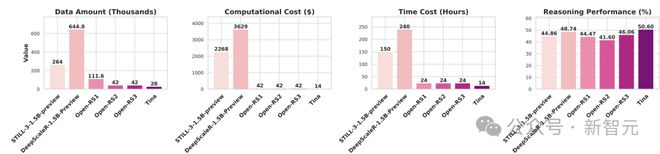
图1:Tina模型与基准模型的整体比较
只经过极少量的后训练,Tina模型在性能上就比基础模型提升了超过20%,并且在表现最好的checkpoint上,在AIME24基准测试中,取得了43%的Pass@1成绩。

在六个推理任务上,Tina模型与相应的全参数训练的最先进(SOTA)模型之间的性能比较
而且,复现表现最佳Tina检查点只需花费9美元,若从头开始复现实验的全部过程,成本也仅为526美元!
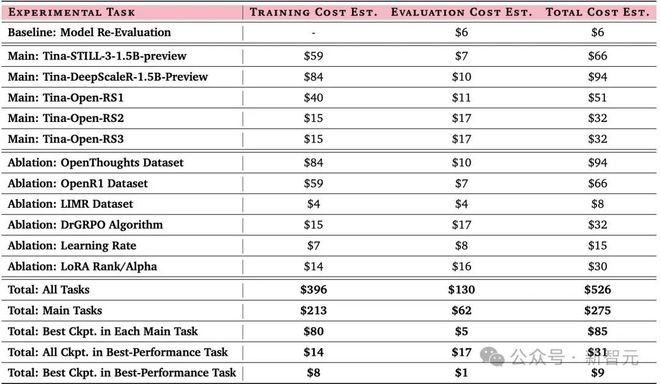
计算成本分解,以美元($)为单位进行衡量
在多个开源推理数据集上,研究者验证了这一发现,并对学习率、LoRA的秩以及强化学习算法进行了消融实验。
总体来看,研究者发现Tina的性能在这些因素上都比较稳定,表现出较强的稳健性。

在六个推理任务上,对Tina模型的变体进行性能评估
此外,研究者特意使用了固定的超参数,避免了超参数调优所带来的成本,并进一步减少了计算开销。
但为什么呢?
初步的猜想
那么,为什么使用LoRA+强化学习在推理任务中会如此高效且效果显着呢?
在Tina模型的计算扩展行为以及训练动态中,研究者发现了一些有趣的模式。
观察一:在LoRA模型中,训练所使用的计算量增加反而会降低模型性能,这与全参数模型的表现相反。
这一发现揭示了一个现象:「更少的计算,反而能带来更好的性能」。

Tina模型与基线模型在推理任务上的性能比较,同时对比了它们的训练计算复杂度(以FLOPs为单位)
观察2:在训练大多数Tina模型时,研究者注意到与问题格式相关的指标(如格式奖励、答案长度),会在训练过程中发生显着变化,而这种变化在准确性相关的指标上并不明显。
有趣的是,性能最佳的checkpoint,往往出现在这些格式指标发生变化的时候。
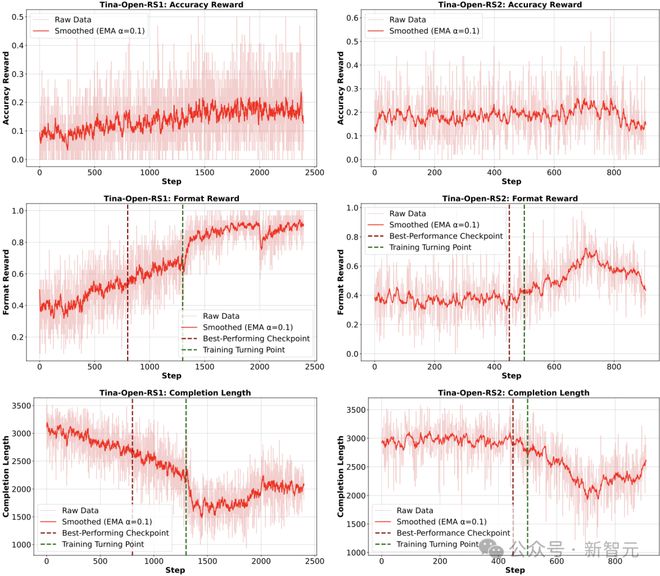
基于LoRA的强化学习中的阶段转
根据这些观察,研究者提出了关于基于LoRA的强化学习后训练方法有效性的假设:
Tina训练方法之所以有效且高效,是因为LoRA能够迅速调整模型,让模型适应强化学习所奖励的推理结构,同时保留基础模型的大部分原有知识。
作者介绍
王上上(Shangshang Wang)

王上上(Shangshang Wang),目前是南加大的计算机科学和人工智能专业一年级博士生。
在上海科技大学,他完成了计算机科学的本科和硕士学位。
他的研究兴趣包括大语言模型(LLM)推理、测试时计算效率、人工智能在科学中的应用(Ai4science)、强化学习(RL)和带约束的优化算法(例如多臂老虎机问题)。
参考资料:
https://arxiv.org/abs/2504.15777
https://shangshangwang.notion.site/tina
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/7046.html