


编辑:编辑部 YZH
【导读】昆仑万维Skywork-R1V 2.0版本,开源了!这一次,它的多模态推理实现了再进化,成为最强高考数理解题利器,直接就是985水平。而团队也大方公开了各项技术秘籍,亮点满满。可以说,R1V 2.0已成为团队AGI之路上的又一里程碑。
就在刚刚,全球首个工业界多模态推理模型Skywork-R1V,再次重磅升级!
此前,R1V 1.0首次成功实现了「强文本推理能力向视觉模态的迁移」,才短短一个月后,Skywork-R1V 2.0就强势上线了。
现在,R1V 2.0的所有资源已全面开源,可以预见,多模态推理社区将迎来新一轮发展。

模型权重:https://huggingface.co/Skywork/Skywork-R1V2-38B
技术报告:https://arxiv.org/abs/2504.16656
代码仓库:https://github.com/SkyworkAI/Skywork-R1V
可以说,R1V 2.0的诞生,不仅推动了开源多模态大模型在能力边界上的突破,更为多模态智能体的搭建提供了全新的基座模型!
R1V 2.0参加高考,已是优秀的985选手
可以毫不夸张地说,R1V 2.0是目前最好、最开放的开源多模态推理模型。
话不多说,我们直接给它上高考题。
首先,就是2022江苏的高考物理真题。

R1V2.0拿到题后,开启了思考模式。
首先,它回忆了一下法拉第电磁感应定律的内容,然后分析了题目的具体条件,得出结论:关键点就在于,确定哪个区域内的磁场变化会对产生电动势起作用。

代入法拉第定律后,模型计算得出了感应电动势的大小。然后还进行了一番额外思考,确定选A没错。


再来看2021年的一道高考物理真题。
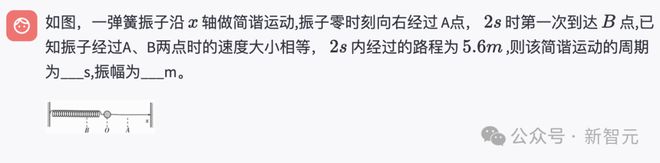
在经过严谨而详细的分析后,R1V 2.0给出了正确的推理和答案。

接下来,是2022广东高考物理卷。

经过思考后,模型得出结论:每个线圈的电动势振幅可能只与匝数相关,而频率则完全一致,因为它们共享同源的磁场变化来源,因而选项B是对的。
在后续分析中,它还相继排除了其他答案的正确性。


下面是一道生物选择题,来自2022年的福州模拟生物卷。

在思考过程中,模型首先回顾了隐性突变、等位基因等基本概念。
然后逐步判断出,选项B是错误的,因为它忽略了插入引起的移码效应所导致的更多氨基酸变化。

而后,它还逐一分析出,选项A、C、D都是正确的。

2022年的福建高考化学选择题,模型也给出了正确选项B。

它经过思考,逐一判断出了A、C、D的错误在哪里。

总之,面对图文并茂、逻辑复杂的高考题目,R1V 2.0展现出了完整的图像理解与推理能力,答案准确率极高,充分展示了自己的实战水平。
可以说,现在就是直接让R1V 2.0去参加高考,考上985也不在话下了。
数学推理、编程能力,又有显着跃升
总的来说,R1V 2.0不仅在高考难题的深度推理中表现出色,还在通用任务场景中展现出强大的广度。
它真正实现了「深度+广度」统一,成为开源多模态模型新标杆。
在多个权威基准测试中,R1V 2.0相较于R1V 1.0在文本与视觉推理任务中均实现显着跃升。
在数学推理、编程竞赛、科学分析这类专业领域,以及创意写作、开放式问答这类通用任务,它的表现都令人眼前一亮。
在视觉能力上,R1V 2.0的视觉理解和深度思考能力让人印象深刻。
它在MMMU上拿下了73.6分的开源SOTA;在Olympiad Bench上以62.6分遥遥领先;并在MathVision,MMMU-PRO与MathVista等视觉推理榜单上,都取得极佳的成绩,在开源模型中一骑绝尘,甚至可以追平部分闭源商业模型。

R1V2.0的视觉推理能力,在开源模型中明显脱颖而出

R1V2.0已有潜力追赶闭源模型
而在文本推理方面,在AIME2024和LiveCodeBench等挑战中,R1V 2.0直接拿下了78.9和63.6的高分,表现出的数学和代码理解能力,已经达到了人类专家级别。

与专业推理模型相比,R1V2.0展现出良好文本推理能力
下图中,是一道高考几何题,R1V 2.0在理解题干基础上,还要理解图中几何要素,然后根据视觉推理,逐步得出正确的答案。

如此可见,R1V2.0是目前最兼顾视觉和文本推理,且最开放的开源多模态推理模型之一。
突破性技术创新,持续迭代
多模态大模型,如何在「深度推理」和「通用能力」上取得最佳平衡?
这个问题,已经在业界被多次提出。
过度集中于推理任务的训练,可能就会牺牲模型在通用任务上的泛化能力。
昆仑万维团队对此进行了深入探索,他们的对策是——引入全新的多模态奖励模型Skywork‑VL Reward及规则驱动的混合强化训练机制。
它们在显着增强推理能力的同时,进一步稳固了模型在多任务、多模态场景中的稳定表现与泛化能力。
为多模态、强化学习而生的奖励模型
强化学习在VLM领域之所以难以进一步发展,关键瓶颈就在于多模态奖励模型的缺乏,因为现有的奖励建模方法,多聚焦于纯文本。
为此,昆仑万维推出了融合多模态推理与通用奖励模型的Skywork-VL Reward——不仅支持多元化奖励判别,还可覆盖各种任务场景。
凭借独特设计与强大性能,它既可为通用视觉语言模型(VLM)提供高质量奖励信号,又能精准评估多模态推理模型长序列输出的整体质量,一举成为多模态强化学习任务中的「杀手锏」。
目前,7B权重和详细技术报告全面开源。

模型权重:https://huggingface.co/Skywork/Skywork-VL-Reward-7B
技术报告:https://github.com/SkyworkAI/Skywork-R1V/blob/main/SkyworkVL_RM.pdf
在多个专业评测榜单中,Skywork-VL Reward的表现都极其突出。
在视觉奖励模型VL-RewardBench基准上,它取得73.1的SOTA,同时在纯文本奖励基准RewardBench上更是拿下了90.1的高分。


实验证明,Skywork-VL Reward有效实现了推理能力与通用能力的协同提升,成功实现「鱼与熊掌兼得」。
引入MPO机制,增强深度推理能力
另外,R1V 2.0引入了MPO(Mixed Preference Optimization,混合偏好优化)机制,充分利用了Skywork-VL Reward奖励模型提供的偏好信号。
比如在这道视觉推理数学题上,Skywork-VL Reward就会给推理简明扼要的答案高分;而充满了无效token「wait」的则直接负分。

再比如,Skywork-VL Reward还能对识别出表格问答中,糟糕答案里的多次重复给予负分,并对精炼的回答给出正反馈得分。

通过这些信号,模型能够进行偏好一致性优化,确保在多任务、多领域的场景下,具备强大的能力。
R1V 2.0的设计延续了R1V 1.0的核心思路,通过提前训练好的MLP适配器,将强大视觉编码器internVIT-6B与原始的强推理语言模型QwQ-32B无缝连接,构建出初始权重位38B多模态模型。
这一巧妙的设计,让R1V 2.0在训练伊始,就具备了初步的多模态推理能力,为后续优化奠定了坚实的基础。
MPO的训练目标为三种损失函数的加权组合:L=wp⋅Lp+wq⋅Lq+wg⋅Lg。其中,Lp是偏好损失(Preference Loss),Lq是质量损失(Quality Loss),Lg是生成损失(Generation Loss)。
通过引入MPO目标,可以让模型学习:
-
响应对之间的相对偏好
-
单个响应的绝对质量
-
以及生成优选响应的完整过程
团队发现,基于MPO的训练策略在提升多模态推理能力方面表现出显着优势。
不仅如此,模型在VisualVQA和幻觉检测基准测试中的表现也优于其未采用MPO 的版本,这就表明,其通用能力得益于更强的推理能力,同时幻觉也得到了大幅度的减弱。
而且,MPO显着优于DPO和传统的SFT方法。
直接偏好优化(DPO)在思维链(CoT)推理任务中,更容易导致响应重复或推理过程混乱,而MPO通过引入多种损失协同优化,有效缓解了这一问题。
此外,研究团队还发现,直接用蒸馏后的SFT数据训练,会导致模型推理能力下跌。
这一点,进一步说明了仅靠监督信号,是难以覆盖复杂推理场景,因此需要更具指导性偏好优化方法去提升模型性能。
为了进一步增强R1V 2.0的深度推理能力,团队采用了「基于规则的群体相对策略优化」(Group Relative Policy Optimization, GRPO)的强化学习算法。
通过同组候选响应之间的相对奖励比较,这一策略引导模型学会更精准选择和推理路径。
然而在实际训练过程中,他们发现了GRPO的一个核心挑战:优势消失(Vanishing Advantages)。
当某个查询组内的所有候选响应均为「全部正确」或「全部错误」时,组内响应的相对奖励差异趋于消失,导致优势归零,无法产生有效的策略梯度。
这种现象在训练后期愈发严重,有效样本从初期60%暴降至10%以下,严重影响了策略更新的效率。
与此同时,另一个独特现象是:视觉模态推理能力与文本模态之间存在互补性。
若是对视觉推理能力进行过度优化,则可能诱发模型产生更多的「幻觉」,进而影响推理准确性与稳定性。
选择性样本缓冲区(SSB)
为此,团队引入了创新性的「选择性样本缓冲区机制」(Selective Sample Buffer, SSB)。
这种高效的样本复用技术可以作用于在线和离线采样过程中,通过保留历史训练中带有非零优势的关键样本,并在后续训练中优先抽样使用,大幅提升了训练信号的质量与密度。
同样,SSB具备三大核心优势:
-
优先采样机制:基于样本优势值的绝对值进行加权抽样,强化对非零优势样本的学习。
-
低成本高回报:通过反复利用高价值样本,极大降低训练所需成本
-
效果显着:即使使用少量样本,模型依然能够获得高效的训练效果

选择性样本缓冲区(SSB)机制通过保留并优先选择具有非零优势的高价值样本来解决优势消失问题
SSB的引入,不仅显着提高了训练的有效样本密度,还有效缓解了模型在训练中期优化空间趋于饱和的问题。
实验已经证明,SSB在R1V 2.0中的应用,是提升推理能力与训练效率的关键一环。
总之,R1V 2.0所采用的多模态强化训练方案,标志着大模型训练范式的又一次重要革新。
Skywork-VL Reward、MPO和SSB的引入,不仅让团队提升了模型在复杂任务中的推理能力,也实现了在多模态任务上的广泛泛化与持续进化。
持续开源,迈向AGI
今年的开源社区,一直在被昆仑万维震撼。
2025年以来,他们不仅在视觉、推理,以及视频生成等领域开源了多款模型,而且还进行了前沿「空间智能」探索。
由此,一步步地构建出了一个全新的模型版图:
-
Skywork-R1V系列:38B视觉思维链推理模型,开启多模态思考时代;
-
Skywork-OR1(Open Reasoner 1)系列:中文逻辑推理大模型,7B和32B最强数学代码推理模型;
-
SkyReels系列:面向AI短剧创作的视频生成模型;
-
Skywork-Reward:性能卓越的文本奖励模型。
值得一提的是,这些项目无一例外都在ModelScope与Hugging Face上大受欢迎,赢得了社区的热烈反响。



不论是在多模态AI、推理模型,还是视频生成等领域,这些成就恰恰体现了昆仑万维的技术领导力。
自从DeepSeek的诞生,全球的AI模型大势已经逆转。
很明显,如今开源模型和闭源系统的差距,正在一步步缩小。

开源不仅仅是技术的共享,更是创新的催化剂。昆仑万维坚信,通过开放权重、技术报告、代码仓库,全球开发者、研究人员能够站在巨人肩膀上,加速AI的迭代和应用。
在这个时代背景下,R1V2的诞生,又多了一重意义。
可以说,它不仅是当前最好的开源多模态推理模型之一,也是昆仑万维迈向AGI路上的又一里程碑。
在未来,昆仑万维还会将「开源、开发、共创」持续到底,推出更多领先大模型和数据集,加速整个行业向AGI的迈进。
参考资料:
https://github.com/SkyworkAI/Skywork-R1V
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/5375.html