


编辑:编辑部 ZJH
【导读】公考行测中的逻辑推理题,是不少考生的噩梦,这次,CMU团队就此为基础,打造了一套逻辑谜题挑战。实测后发现,o1、Gemini-2.5 Pro、Claude-3.7-Sonnet这些顶尖大模型全部惨败!最强的AI正确率也只有57.5%,而人类TOP选手却能接近满分。
就在昨天,OpenAI憋出个大招,放出了o3和o4-mini。
据称,这些模型首次实现了「用图像思考」,堪称视觉推理巅峰之作。
而有这样一类图像推理题,让国内每年都有几百万考生受尽折磨。
看到下面这些熟悉的题,参加过国考或省考的你,是不是DNA动了?

图形推理题,在公务员考试中常常被考生吐槽:题难、奇葩,逻辑怪异,套路满满,甚至十分「反人类」!


既然如今的AI这么强,让人类考生直呼变态的图形推理,它们做得出吗?
CMU的研究者,这次就用公务员考试真题来实测了一把!
他们建立了一个将多模态推理与领域知识分离的新基准——VisualPuzzles,来考验AI的视觉拼图解决能力。
具体来说,研究者从多个来源精心挑选或改编了1168道图文逻辑题,其中一个重要来源便是中国国家公务员考试行测中的逻辑推理题(没错,真·考公难度)。

论文链接:https://arxiv.org/abs/2504.10342
项目链接:https://neulab.github.io/VisualPuzzles/
而测试结果,可以说令人震惊:
-
最强模型的正确率也只有57.5%,都低于人类5%最差水平
-
普通开源模型的正确率更惨淡,仅有约30%~40%
-
相比之下,人类顶尖选手的正确率可以接近满分,可见在纯逻辑推理方面,模型与人仍有明显鸿沟
看来,模型们还是上不了岸了啊……

此次研究的其他发现如下。
知识≠推理:在像MMMU这样的知识密集型基准上,推理与知识有很强的相关性,但在VisualPuzzles上则不然
更大的模型=更好的知识,但不一定有更好的推理能力
「思考」模式并不总是有效。更多的token=更好的知识回忆≠更好的推理

不同模型在VisualPuzzles上的表现,成绩从高到低排列;其中前3行为人类前5%,前50%和倒数5%
模型 vs 人类
如何测试多模态大模型的能力?
即便取得好成绩,AI到底是学会了推理,还是说只是记下了特定领域知识?
现有的多模态基准测试,往往将推理能力与领域专业知识混为一谈,难以单独评估通用推理能力。
CMU提出的VisualPuzzles,目的就是针对视觉推理的基准,同时故意减少对专业知识的依赖。
VisualPuzzles包含五大类题型:算法推理、类比推理、演绎推理、归纳推理和空间推理。
实验表明,与像MMMU等过去的基准相比,VisualPuzzles需要的领域特定知识明显更少,而对复杂推理的要求更高,从而能更准确地评估真正的多模态推理能力。
评估结果显示,最先进的多模态大语言模型在VisualPuzzles上的表现,始终落后于人类水平。
而且在知识密集型基准上表现强劲的模型,在专注推理且依赖较少知识的任务上,未必能够取得成功。
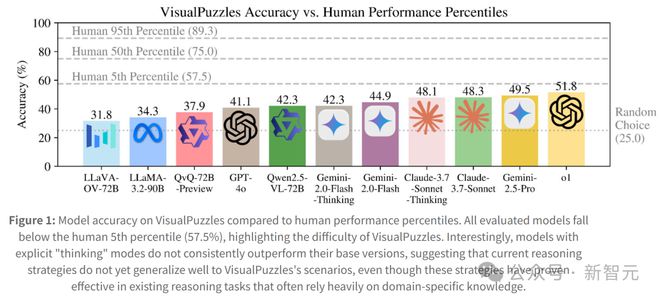
图1:模型在VisualPuzzles上的准确率与人类表现百分位数的比较。所有评估的模型都低于人类5百分位数(57.5%)
有趣的是,具有显式「思考」(think)模式的模型并不总是比基础版本好。
此外,增强推理的技术手段,在不同模型和任务类型中收效参差不齐。
研究者并未发现模型规模与性能存在明确关联。
这说明当前的推理策略还不能很好地泛化到VisualPuzzles。
大模型「显眼包」解题大赏
下面,我们来看一看o1、Gemini-2.5 Pro、Claude-3.7-Sonnet这些顶尖的明星大模型,在做公务员考试行测中的逻辑推理题时,都会是什么样子。
(人类选手们也可以试试,看这些题自己能不能做得出。)

下面这道题中,给出了一对按特定角度排列的椅子,答题人需要选择与题干中椅子角度相匹配的选项。

Claude-3.7-Sonnet针对这道题开启了思考模型,一通操作猛如虎——
「这些椅子相隔180度,它们是以侧面视角展示的。从角度来看,任何一个选项都是正确的。然而,更仔细地观察它们的具体方向:原始椅子以完美的侧面视角展示。选项A展示了与问题中的排列最匹配的最干净的侧面视图,所以我选A。」

然而,这道题的正确答案是C。

下面这道题,要求数出图中的三角形比正方形多几个,看起来是小学数学题的级别。

Claude-3.7-Sonnet-Thinking经过一番长长的思考,给出答案D,然而正确答案是C。

下图中有几个左手?Claude-3.7-Sonnet-Thinking表示答案是B,然而正确答案是C。


以上这几道,只是小试牛刀而已。接下来,就要上让人类考生都瑟瑟发抖的公考行测题了,准备好。
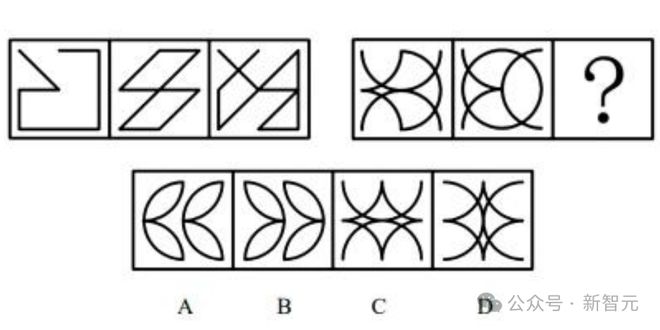

Claude-3.7-Sonnet-Thinking给出的答案是C,然而正确答案是A。

然而这次不能怪它做错了,我们自己也没做出来……
而接下来这道题,Claude-3.7-Sonnet-Thinking的表现就十分亮眼了。
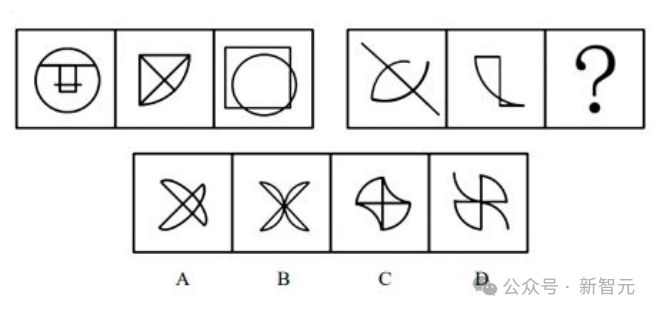

这次,模型经过一番推理后,给出了正确答案——C!

这道判断村庄道路图的题,有一定难度。


模型给出了答案D,然而正确答案是C。
下面这道题,对人类来说是很简单的,但Claude-3.7-Sonnet-Thinking依然做错了,它给出的答案是A。
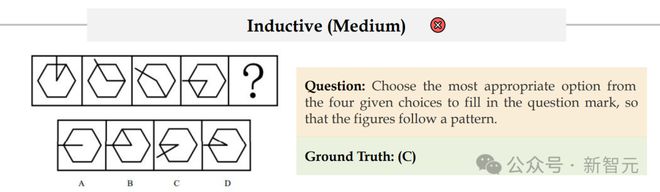
而有时对人类看起来并不直观、有一定难度的题,模型却反而能做对,比如下面这道。

Claude-3.7-Sonnet-Thinking给出了正确答案——C。

总体而言,行测中这类找规律的归纳题,模型偶尔能做对。


在空间题中,模型也有一定概率能得出正确答案。
有趣的是,有些对人类很简单的题,它反而不行,证明了AI模型的空间推理能力跟人脑还是有差距。





最后,想问问人类读者:你做对了几道题,赢过AI了吗?
三个不等式
正如前文所言,新研究主要揭示了3个「不等式」:
1. 知识≠推理
2. 更大的模型=更好的知识≠更好的推理
3. 更多的token≠更好的推理
知识≠推理
在非专业场景中评估通用推理能力的核心在于,厘清推理能力与领域专业知识的边界。
为此,研究人员提出了一个专注视觉推理、并有意弱化对专业知识依赖的基准数据集——VisualPuzzles。
下面,我们就来看看这个VisualPuzzles,到底有多难:
-
题型多样:包括算法类、类比类、逻辑类、归纳类、空间类五大推理类型,覆盖了常见的逻辑与思维模式。
-
难度分布:Easy/Medium/Hard分别占比46%/39%/15%,涵盖从入门到骨灰级的思维挑战。
-
多模态选项:57%是图片选项,43%是文字选项,这样可以测试模型对不同模态信息的推理整合。
-
语言要求低:题干大部分使用基础英文词汇,以降低阅读障碍,突出对视觉和逻辑本身的考察。
其中,五大推理类别具体为:
1. 算法推理:涉及对算法规则进行推理。
2. 类比推理:需要分析一对实体之间的关系。
3. 演绎推理:通过已知前提推理得出逻辑结论。
4. 归纳推理:侧重于从观察到的模式中概括出规则。
5. 空间推理:需要解释和操作空间关系。

表1:VisualPuzzles的题型和难度分布等统计数据
除了难度极高之外,VisualPuzzles相比于现有的基准,还更能反映模型的推理能力,而不是对知识的记忆能力。
为了证明这一点,研究者特意做了一波验证:
首先,让GPT-4o为两类数据集各50道随机选题生成「知识概念检查清单」。
其中,每份清单包含针对原始问题所需背景知识的具体提问。比如说,如果某题需理解两条物理定律,那么清单会要求分别解释这两条定律。通过统计每道题对应的检查清单条目数量,可量化问题的知识密集程度。
结果显示,对于单道题平均需要的知识点:MMMU是3.9个,VisualPuzzles是1.1个。

表3:每个实例在MMMU与VisualPuzzles上生成的平均知识概念问题数量
接着,测量模型在两个基准测试上的知识准确率(即正确回答知识检查清单问题的能力)。
其中,知识准确率和推理能力无关,反映了模型在不依赖推理的情况下,已经掌握的所需知识量。
结果显示:
-
VisualPuzzles:多数模型知识准确率超过90%
-
MMMU:大多数模型准确率不足60%,较小模型常低于50%
-
只有最大规模的模型在MMMU上接近80%准确率
也就是说,MMMU对领域专业知识的强依赖性,而VisualPuzzles所需知识储备已普遍存在于现有模型中——基本没有「超纲题」。
如果推理成绩和知识掌握程度的相关性高更高,那么可以说知识=推理。
但下图描述了知识准确率和推理准确率的相关性:
-
在MMMU中(左图),知识掌握程度和推理成绩相关性高达0.8
-
在VisualPuzzles中(右图),这一相关性降至0.4
也就是说,在VisualPuzzles中模型无法只靠自己学过的知识点,答出实际需要推理的题目。

图2(下):推理准确率与知识准确率之间的关系散点图及趋势线
更大的模型≠能答对题
现在,我们已经有了不「超纲」且很难通过「背题」答出来的测试集,接下来就可以测测模型的表现了。
图2(上)绘制了推理准确率和模型参数规模的关系,可以看到:
-
MMMU:模型参数规模越大,知识准确率越高,更大的参数规模通常转化为更高的整体基准表现。
-
VisualPuzzles:与MMMU不同,如果只扩大参数数量,那并不能保证在VisualPuzzles上的表现更好。
换句话说,需要知识时,大模型参数规模越大、预训练知识越多,可能推理越出色。
但在不需要专业知识、只考察纯逻辑思维等推理能力的时候,大模型就开始力不从心了。
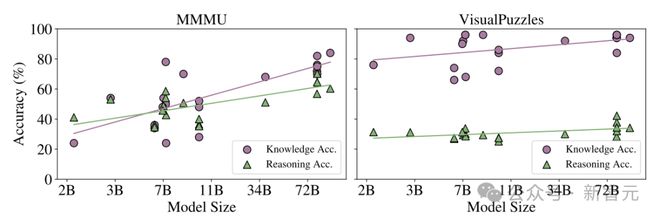
图2(上):MMMU和VisualPuzzles上准确率与模型规模之间的关系散点图及趋势线
长文本≠好推理
按道理说,像是o1,Claude-3.7-Sonnet-Thinking,Gemini-2.0-Flash-Thinking这些看起来「更会思考」的推理模型,应该在逻辑难题上表现更好。
然而在实际的测试中,它们虽然确实会输出更长、更详细的回答,但正确率并没有显着提高。

表4:解决基准问题时所需的逻辑推理步骤百分比

图3:推理模型与其通用对照模型在VisualPuzzles上的准确率和平均完成token数的比较
究其原因,可能有以下几点:
1. 更多文字≠更深入的逻辑推理
模型往往只是在其输出中添加了许多「推理装饰」,但缺乏真正的推理深度。本质上,它仍然在沿用与非思维增强版相同的推理模式。
2. 在知识型题目上有效,但在纯逻辑题上收效甚微
在需要调用大量专业知识(如医学、法律、物理定律)的题目上,长文本有助于「回忆」相关知识。
但在VisualPuzzles这样依赖逻辑推理(而非记忆库)的测试中,它们就显得力不从心。
推理套路不一定管用
为了更好地理解这种差异,研究者分析了模型在长思维链中,常用的两种推理策略:
-
Branching(分支推理)
-
Revalidation(回溯验证)
如图4所示,分析揭示了基准之间的显着对比,其中:
-
左图比较了Claude-3.7-Sonnet和Claude-3.7-Sonnet-Thinking在MMMU和VisualPuzzles上的准确率
-
中图显示了每种推理模式的频率
-
右图展示了这些推理模式与基准准确率的相关性
可以看到,在对知识依赖更强的任务(如MMMU)中,这些策略可以帮助模型回忆更多事实,从而提高正确率。
然而在VisualPuzzles上,这些行为虽然出现得更为频繁,但成效却几乎为零。
也就是说,模型可能只是走个过场,并没有真推理。
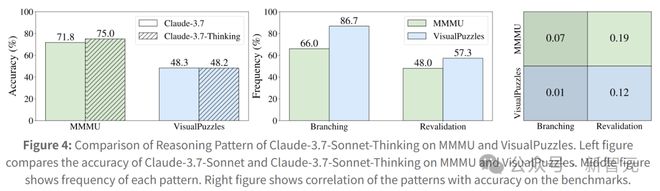
图4:Claude-3.7-Sonnet-Thinking推理模式在MMMU和VisualPuzzles上的比较
值得一提的是,模型在MMMU和VisualPuzzles中的回答策略,是有明显差异的。
在MMMU中,模型倾向于采用基于选项的策略——即利用提供的选项早期排除不太可能的答案,并选择最相关的选项,通常在不显式解决问题的情况下进行。
相反,在VisualPuzzles中,模型更频繁地采用「回答优先」策略,即在比较结果与选项之前,独立尝试解决问题。

表5:回答策略
模型为何「一路滑铁卢」?
对此,研究者分析认为:
-
模型对空间信息理解仍不稳定:视觉感知环节常出错,尤其涉及物体位置、形状与角度等
-
最大且最致命的问题依然是:缺乏深层逻辑推理能力

图7:Claude-3.7-Sonnet-Thinking的错误分布
推理能力可以「迁移」吗?
对于人类而言,每个推理类别可能涉及不同的认知或心理过程,因此一个类别的表现可能无法迁移到另一个类别。
但对于模型来说,其相关性热图讲述了一个不同的故事。
研究者观察到推理类别之间存在显着的强相关性,相关值从0.11到高达0.94不等。
特别是,算法推理和演绎推理之间的相关性很高(0.94),而算法-类比和演绎-类比等其他组合也表现出较强的关联。这表明模型的表现倾向于在不同类别之间进行泛化。
然而,这种泛化可能只是因为模型正在利用某些通用的「表面模式」或捷径,并不代表具备了真正多样化的推理能力。

图6:推理类别之间的相关性热图(所有评估模型的平均值)
总结
VisualPuzzles的出现揭示了一个重要的事实:
-
依靠记忆力(大规模训练中的知识)不足以让模型在真正的推理题中表现出色;
-
大模型的推理能力仍与人类存在显着差距,尤其在不依赖专业知识、纯逻辑思维的场景中。
这也为未来的多模态大模型发展指明了努力方向:
-
如何在训练过程中强化推理结构而非单纯依赖知识?
-
如何设计出兼具复杂逻辑与通用认知的新型网络或推理模块?
-
是否还能扩展到多图、多步骤或动态场景的推理?
总之,在不断扩大规模、补充知识的同时,也别忘了走向真正的理解与推理。
毕竟,上岸不光要背知识点,更要有「硬核逻辑」做支撑!
作者介绍
Yueqi Song

Yueqi Song即将进入卡耐基梅隆大学(CMU),攻读自然语言处理(NLP)方向的博士学位,导师是Graham Neubig教授。
此前,她在CMU获得了计算机科学与统计与机器学习双学士/硕士学位。 她的研究兴趣主要包括多模态大语言模型、AI Agent等领域,参与的论文曾在EMNLP获得最佳论文奖。
Tianyue Ou

Tianyue Ou是卡内基梅隆大学的硕士生。此前在约翰霍普金斯大学获得了计算机科学学士学位。
他的研究兴趣集中在LLM Agents、合成数据生成与LLM推理。
在进入学术研究之前,他曾在Meta担任机器学习工程师,主要研究推荐系统。
Graham Neubig

Graham Neubig是卡耐基梅隆大学的教授,也是All Hands AI的首席科学家,致力于构建软件开发的AI智能体系统。
他的研究方向聚焦于机器学习与自然语言处理,特别是大语言模型的基础研究与应用,涵盖问答系统、代码生成、多语言处理、以及模型评估与可解释性等主题。
Xiang Yue

Xiang Yue是卡耐基梅隆大学的博士后,导师是Graham Neubig教授,研究方向为自然语言处理(NLP)与大语言模型(LLM)。
他于俄亥俄州立大学获得计算机博士学位。他的研究目标是理解并提升大语言模型的推理能力,并致力于增强模型的可靠性。他领导并参与了多个大模型推理的基准,如MMMU等。
参考资料:
https://neulab.github.io/VisualPuzzles/
https://x.com/yueqi_song/status/1912510869491101732
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/4681.html