


编辑:犀牛 英智
【导读】悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。
当谈到AI为何能从「预测下一个词」中诞生智慧时,Ilya Sutskever曾用一个生动的比喻来解释。
想象你在读一本悬疑小说,如果仅凭前面的线索就能在最后一页推断出罪犯是谁,那么你对这个故事的理解无疑是深刻的。
同样,AI通过学习海量文本,掌握了从字面到语义的「线索」,展现出惊人的智能。

受此启发,UCSD的华人研究者用游戏《逆转裁判》(Ace Attorney)测试AI的推理能力。
《逆转裁判》以错综复杂的故事情节和扣人心弦的法庭对决着称。
这款游戏堪称测试模型的完美舞台:AI化身侦探,收集线索、揭露矛盾,最终挖掘真相。

研究者让当前最顶尖的AI模型(GPT-4.1、Gemini 2.5 Pro、Llama-4 Maverick等)在《逆转裁判》中接受考验,看它们能否喊出「反对!」,扭转案情,揭开谎言背后的真相。

和侦小说一样,模型玩家得把线索、证据串起来,揭露证词中的矛盾,抓住真凶。

测试中,AI模型要参与紧张的法庭盘问环节。它要敏锐地找出证词中的漏洞,拿出正确的证据进行反驳。每个关卡有5次机会,犯错空间有限。

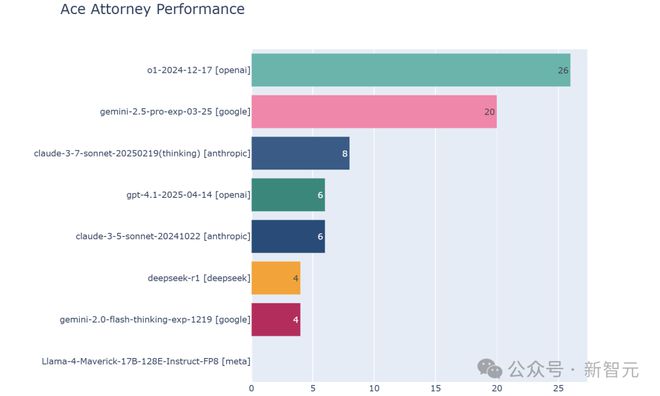
团队测试了多款顶尖的AI多模态模型,包括o1、Gemini 2.5 Pro、Claude 3.7-thinking和Llama-4 Maverick。
结果显示,o1和Gemini 2.5 Pro表现最佳,均晋级第4关。虽然未能通关,但o1在应对最复杂案件时,略胜Gemini 2.5 Pro一筹。
GPT-4.1与Claude 3.5表现相当。尽管GPT-4.1据称比GPT-4o有所提升,但这次测试中的表现与其持平。
Llama-4 Maverick一次没对,零分垫底!
为什么它很难?
《逆转裁判》游戏对AI模型十分困难,主要是因为模型需要有以下能力:
-
长文本推理:需要比对之前的对话和证据,发现证词中的矛盾点。
-
视觉理解:准确识别能反驳虚假陈述的图片。
-
策略决策(游戏设计):动态变化的案件中,决定何时追问、出示证据或暂不行动。不仅要给出答案,还要在正确时机采取行动。
游戏设计要求AI把理解转化为有情境依据的行动,让它不只局限于处理文本或视觉任务。
因为AI需要推理情境化的行动空间,而非简单死记硬背,所以更不容易出现过拟合。
性价比哪家强
Gemini 2.5 Pro重新定义了性价比。
在性能相当的情况下,Gemini 2.5 Pro比o1-2024-12-17便宜6-15倍,甚至比GPT-4.1还便宜一点。
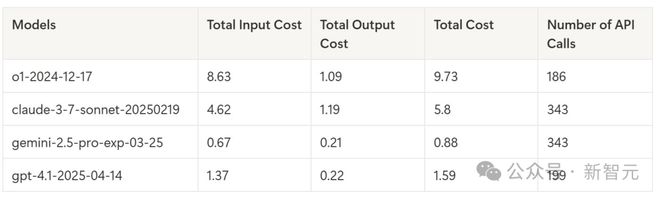
通过第1关的模型成本对比中,o1的API调用次数最少,总成本却是最高的。
调用次数体现的是策略,而非推理能力。因为深入挖掘证词,自然会触发更多请求。
进入更高关卡后,随着对话篇幅增加,o1的成本激增。
在第2关(一个很长的案例)中,o1的成本超过$45.75,而Gemini 2.5 Pro仅需$7.89,差距惊人!
注意:
-
Gemini 2.5 Pro使用内置token计数方法,将所有图片都按258个token计算,因此实际成本可能略高。
-
o1隐藏推理内容存在不确定性,其输出成本也可能被低估了。

目前团队已将项目开源,可以在里面查看如何设置游戏和LLM。

项目地址:https://github.com/lmgame-org/GamingAgent
除此之外,项目中还有更多经典游戏能测试AI模型的性能。
推箱子游戏
推箱子(Sokoban)是一款经典的单人游戏,以深邃的策略性着称。
推箱子的玩法简单直观,但挑战性极高。
玩家在一个由方格组成的迷宫中操作角色,通过逻辑思考和规划,将箱子推到目标位置。

2048游戏
这是一款数字益智游戏,玩家通过滑动方块合并相同数字,最终目标是合成2048方块。
策略上,应该优先保持最大数字在角落,规划滑动方向以避免方块堆积,灵活调整以应对随机出现的数字。
下图可以看出,Claude 3.7 玩起2048来还是挺丝滑的,能持续玩很多步。相比之下,GPT 4o不知道为什么,玩上几步就开始卡上了。


俄罗斯方块
俄罗斯方块是一款风靡全球的经典游戏。
玩家需通过移动和旋转方块,拼凑完整横行以消除得分,尽可能延长游戏时间或获得高分。

此外,还有超级马里奥、糖果粉碎传奇等多款游戏。
参考资料:
https://x.com/haoailab/status/1912231343372812508
https://huggingface.co/spaces/lmgame/game_arena_bench
https://lmgame.org/
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/4317.html